scrub-jay-RADseq-vignette
scrub-jay-RADseq-vignette.RmdThis is a real-world example of using the SNPfiltR package to filter a moderately sized RADseq dataset. This dataset includes 115 samples, and > 200,000 unfiltered SNPs. Reading this unfiltered vcf file into Rstudio took ~1 minute on my personal laptop, and individual functions took between a few seconds and a few minutes to finish. Overall, this dataset is a great example of the power of R and the SNPfiltR package to streamline the filtering process for moderately sized reduced-representation genomic datasets.
Optional Step 0: per sample quality control
Do quality control per sample before performing SNP calling. I have written an RMarkdown script that uses the R package fastqcr to generate a report visualizing the quality and quantity of sequencing for each sample, and recommending a subset of samples to be immediately dropped before parameter optimization (specifically useful for RADseq data). The only modification necessary for this script is the path to the folder containing the input .fastq.gz files and the path to your desired output folder. An example report generated using this script can be seen here. Because the fastq.gz files for your experiment may be large and handled remotely, an example bash script for executing this RMarkdown file as a job on a high performance computing cluster is available here.
Because this dataset was not overly large, and I used a reference based assembly that doesn’t depend on each sample contributing to the de novo building of RAD loci, I chose to skip this step and do all of the per sample quality filtering in R. I started below by reading in the vcf file using the aforementioned vcfR package:
Step 1: read in vcf file as ‘vcfR’ object
Read in vcf file using vcfR
library(SNPfiltR)
#> This is SNPfiltR v.1.0.1
#>
#> Detailed usage information is available at: devonderaad.github.io/SNPfiltR/
#>
#> If you use SNPfiltR in your published work, please cite the following papers:
#>
#> DeRaad, D.A. (2022), SNPfiltR: an R package for interactive and reproducible SNP filtering. Molecular Ecology Resources, 00, 1-15. http://doi.org/10.1111/1755-0998.13618
#>
#> Knaus, Brian J., and Niklaus J. Grunwald. 2017. VCFR: a package to manipulate and visualize variant call format data in R. Molecular Ecology Resources, 17.1:44-53. http://doi.org/10.1111/1755-0998.12549
library(vcfR)
#>
#> ***** *** vcfR *** *****
#> This is vcfR 1.14.0
#> browseVignettes('vcfR') # Documentation
#> citation('vcfR') # Citation
#> ***** ***** ***** *****
#read in vcf as vcfR
vcfR <- read.vcfR("~/Desktop/aph.data/populations.snps.vcf")
### check the metadata present in your vcf
vcfR
#> ***** Object of Class vcfR *****
#> 115 samples
#> 87 CHROMs
#> 210,336 variants
#> Object size: 685.5 Mb
#> 57.1 percent missing data
#> ***** ***** *****
#generate popmap file. Two column popmap with the same format as stacks, and the columns must be named 'id' and 'pop'
popmap<-data.frame(id=colnames(vcfR@gt)[2:length(colnames(vcfR@gt))],pop=substr(colnames(vcfR@gt)[2:length(colnames(vcfR@gt))], 3,11))Step 2: quality filtering
Implement quality filters that don’t involve missing data. This is because removing low data samples will alter percentage/quantile based missing data cutoffs, so we wait to implement those until after deciding on our final set of samples for downstream analysis
Note:
I like to start with a completely unfiltered vcf file, in order to implement a cohesive, fully documentable filtering pipeline in R. However, if I have a very large unfiltered vcf file that I would like to work with in Rstudio, I sometimes perform hard filtering, or implement some conservative percentage based filters (e.g., remove all SNPs above 90% missing data) via command-line calls to the program VCFtools, in order to reduce the size of the starting vcf that I need to read into Rstudio. Just be aware that once you drop low data samples, your previously enforced (per SNP or locus) missing data % will no longer be accurate. VCFtools has faster implementations of some of the same filters implemented here, and really shines with large datasets. The R-based implementations of these filters in SNPfiltR offers interactive visualization in a cohesive R-based pipeline, but be aware that reading in excessively large files to Rstudio (typically, > 1 Gb in my experience) can cause R to hang and crash. Luckily, I have found that variant sites only vcf files for most reduced-representation genomic datasets are under this size, and can be handled efficiently using Rstudio on a personal computer.
Note:
Jon Puritz has an excellent filtering tutorial that is focused specifically on filtering RADseq data Multiple functions in SNPfiltR were generated in order to follow the guidelines and suggestions laid out in this tutorial. We can follow these guidelines for hard filtering (he suggests minimum depth=3, gq =30), and can implement suggested filters like allele balance and max depth, here in R using SNPfiltR.
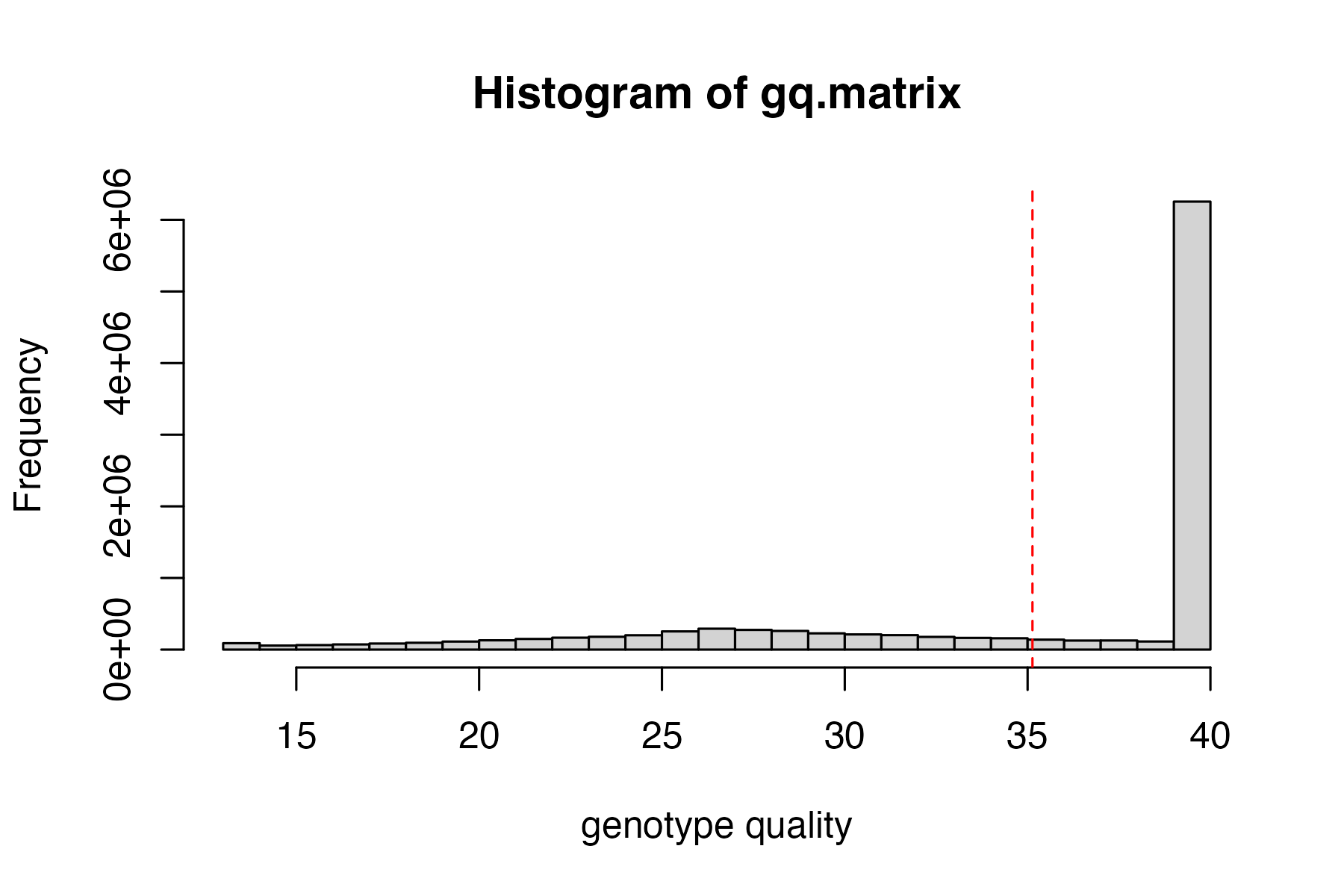
start by visualizing the distributions of depth of sequencing and genotype quality among called genotypes, then set appropriate cutoffs for both values for this dataset.
#visualize distributions
hard_filter(vcfR=vcfR)
#> no depth cutoff provided, exploratory visualization will be generated.
#> no genotype quality cutoff provided, exploratory visualization will be generated.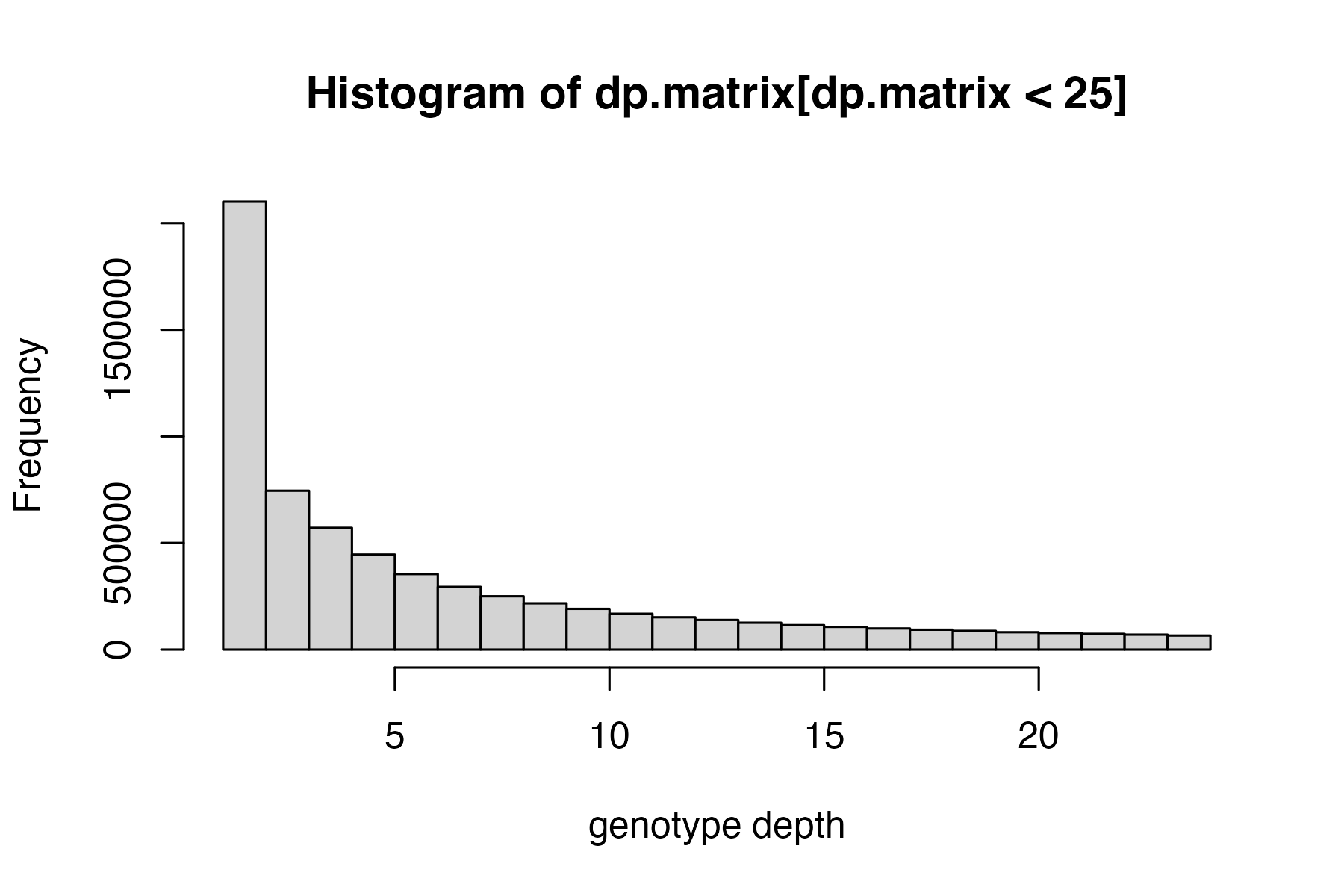
#> ***** Object of Class vcfR *****
#> 115 samples
#> 87 CHROMs
#> 210,336 variants
#> Object size: 685.5 Mb
#> 57.1 percent missing data
#> ***** ***** *****
#hard filter to minimum depth of 5, and minimum genotype quality of 30
vcfR<-hard_filter(vcfR=vcfR, depth = 5, gq = 30)
#> 32.92% of genotypes fall below a read depth of 5 and were converted to NA
#> 2.01% of genotypes fall below a genotype quality of 30 and were converted to NA
#remove loci with > 2 alleles
vcfR<-filter_biallelic(vcfR)
#> 0 SNPs, 0% of all input SNPs, contained more than 2 alleles, and were removed from the VCF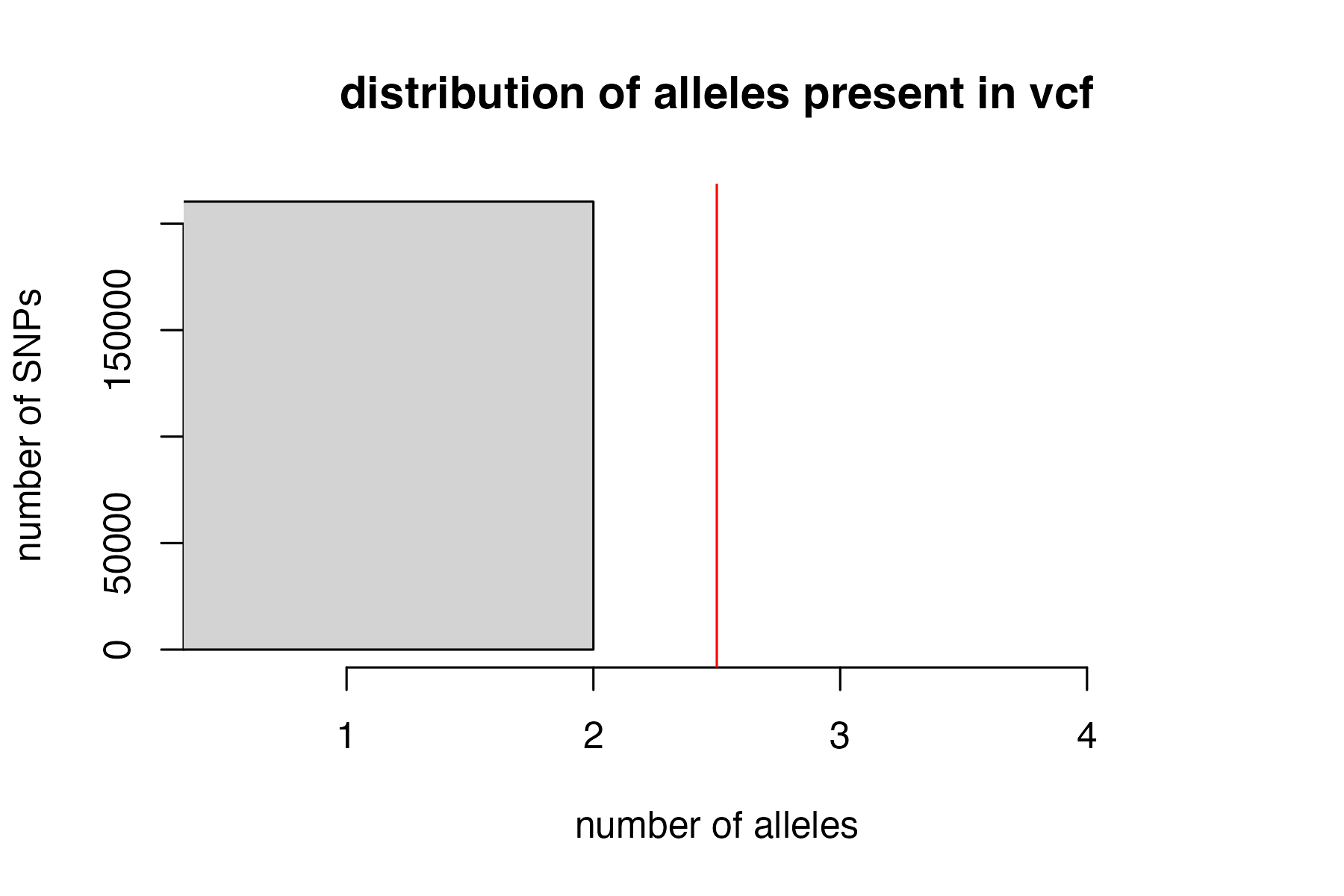
Then use this function to filter for allele balance
From the Ddocent SNP filtering tutorial “Allele balance: a number between 0 and 1 representing the ratio of reads showing the reference allele to all reads, considering only reads from individuals called as heterozygous, we expect that the allele balance in our data (for real loci) should be close to 0.5”
the SNPfiltR allele balance function will convert heterozygous genotypes to missing if they fall outside of the .25-.75 range.
#execute allele balance filter
vcfR<-filter_allele_balance(vcfR)
#> 7.56% of het genotypes (0.39% of all genotypes) fall outside of 0.25 - 0.75 allele balance ratio and were converted to NA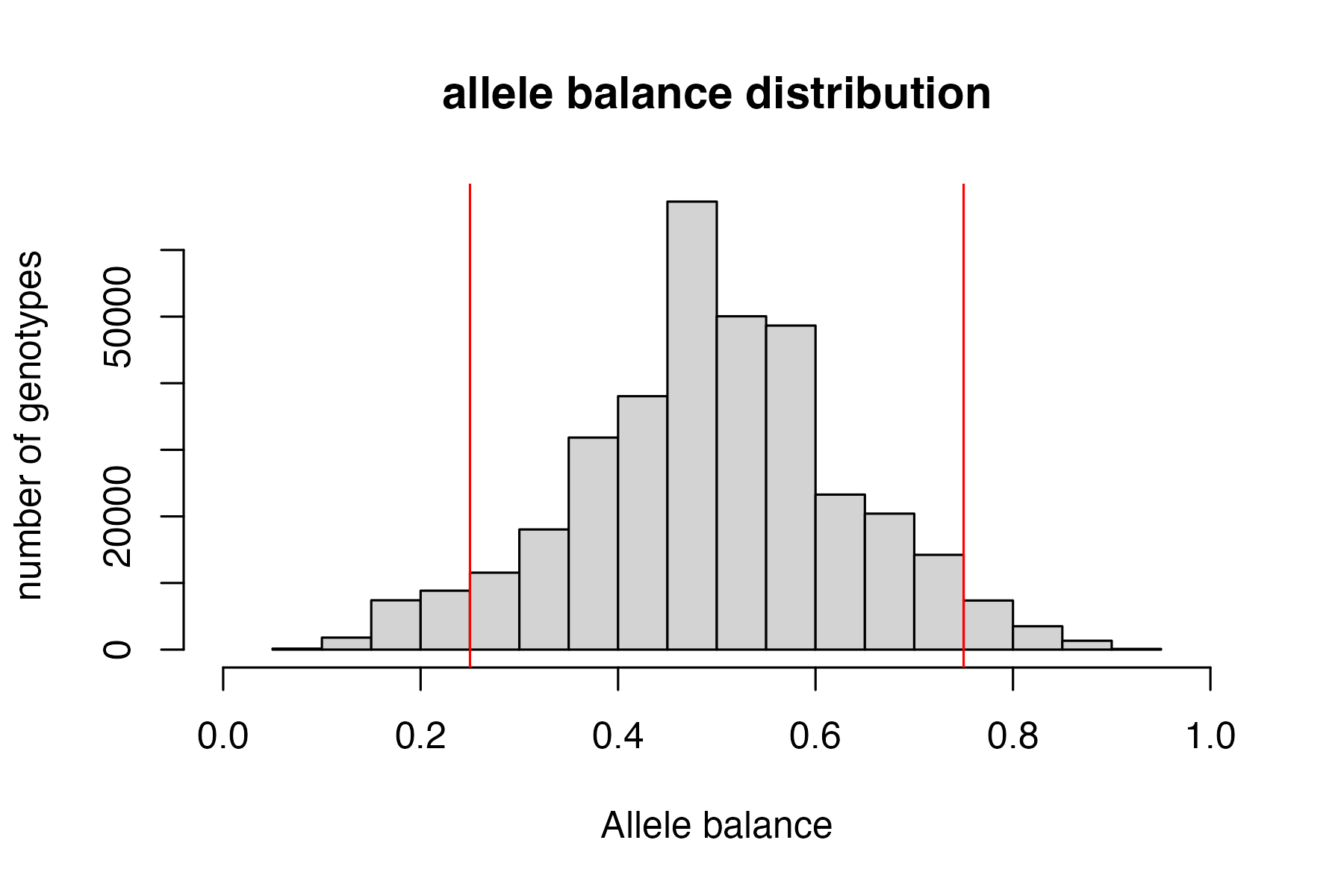
Now we can execute a max depth filter (super high depth loci are likely multiple loci stuck together into a single paralogous locus).
Note:
This filter is applied ‘per SNP’ rather than ‘per genotype’ otherwise we would simply be removing most of the genotypes from our deepest sequenced samples (because sequencing depth is so variable between samples). By filtering per SNP, we remove the SNPs with outlier depth values, which are most likely to be spuriously mapped/built paralagous loci.
#visualize and pick appropriate max depth cutoff
max_depth(vcfR)
#> cutoff is not specified, exploratory visualization will be generated.
#> dashed line indicates a mean depth across all SNPs of 46.7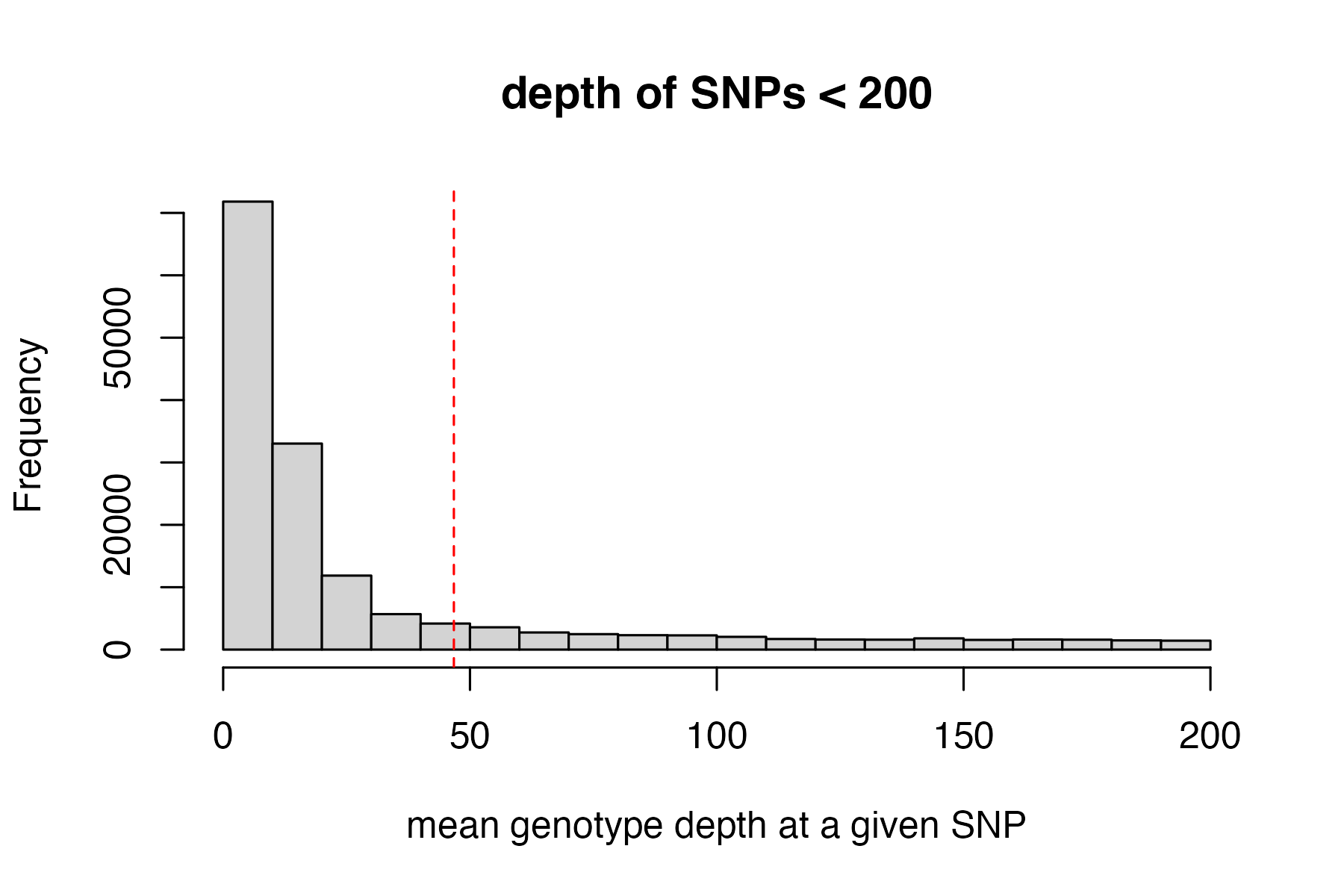
#filter vcf by the max depth cutoff you chose
vcfR<-max_depth(vcfR, maxdepth = 100)
#> maxdepth cutoff is specified, filtered vcfR object will be returned
#> 12.85% of SNPs were above a mean depth of 100 and were removed from the vcf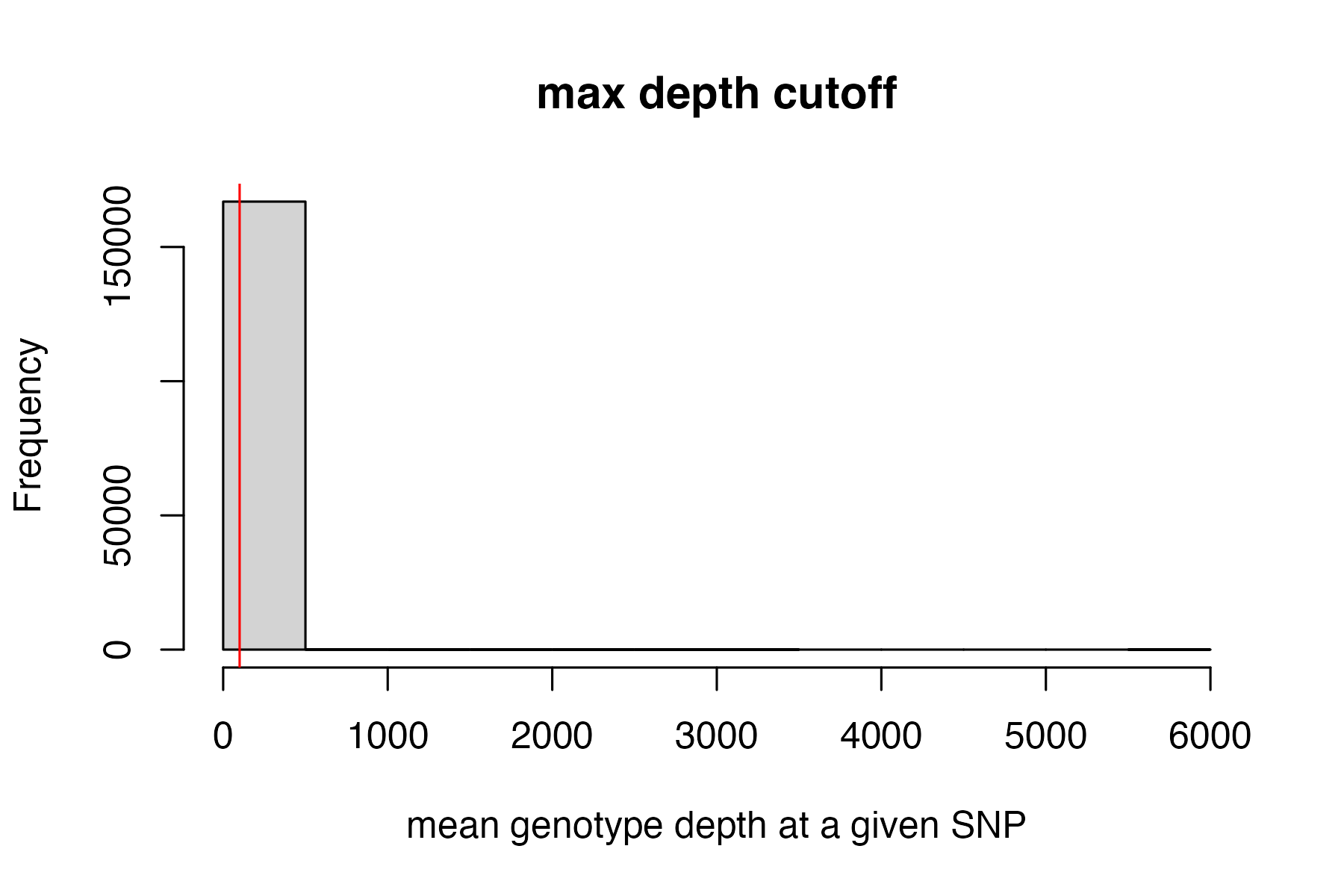
Note:
It may be a good idea to additionally filter out SNPs that are significantly out of HWE if you have a really good idea of what the population structure in your sample looks like and good sample sizes in each pop. For this dataset, which is highly structured (many isolated island pops) with species boundaries that are in flux, I am not going to use a HWE filter, because I don’t feel comfortable confidently identifying populations in which we can expect HWE. Many other programs (such as VCFtools) can filter according to HWE if desired.
#remove invariant SNPs generated during the genotype filtering steps
vcfR<-min_mac(vcfR, min.mac = 1)
#> 55.87% of SNPs fell below a minor allele count of 1 and were removed from the VCF
#check vcfR to see how many SNPs we have left
vcfR
#> ***** Object of Class vcfR *****
#> 115 samples
#> 70 CHROMs
#> 80,885 variants
#> Object size: 283.2 Mb
#> 60.85 percent missing data
#> ***** ***** *****Step 3: set missing data per sample cutoff
Set arbitrary cutoff for missing data allowed per sample.
Determining which samples and SNPs to retain is always project specific, and is contingent on sampling, biology of the focal taxa, sequencing idiosyncrasies, etc. SNPfiltR contains functions designed to simply and easily generate exploratory visualizations that will allow you to make informed decisions about which samples and SNPs are of sufficient quality to retain for downstream analyses, but there is never a single correct option for these cutoffs. In my experience, the best thing to do is to look at your data, look at what effects some reasonable cutoffs would have on your data, and pick one that works for you. Then as you continue to analyze your data, make sure that your arbitrary filtering decisions are not driving the patterns you see, and iteratively update your filtering approach if you are concerned about the effects previous filtering choices are having on downstream results.
We will start by determining which samples contain too few sequences to be used in downstream analyses, by visualizing missing data per sample
#run function to visualize samples
missing_by_sample(vcfR=vcfR, popmap = popmap)
#> Bin width defaults to 1/30 of the range of the data. Pick better value with
#> `binwidth`.
#> Bin width defaults to 1/30 of the range of the data. Pick better value with
#> `binwidth`.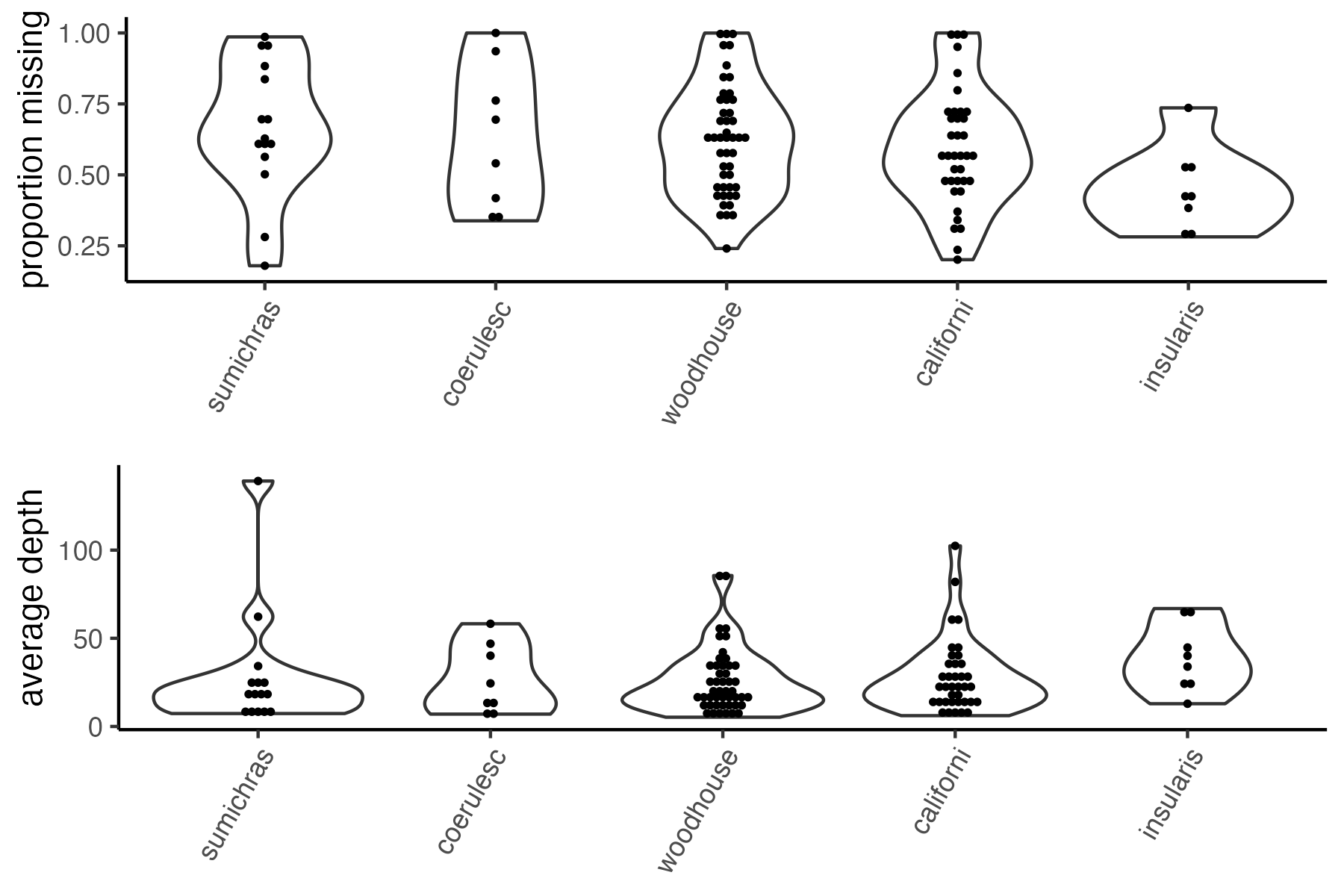
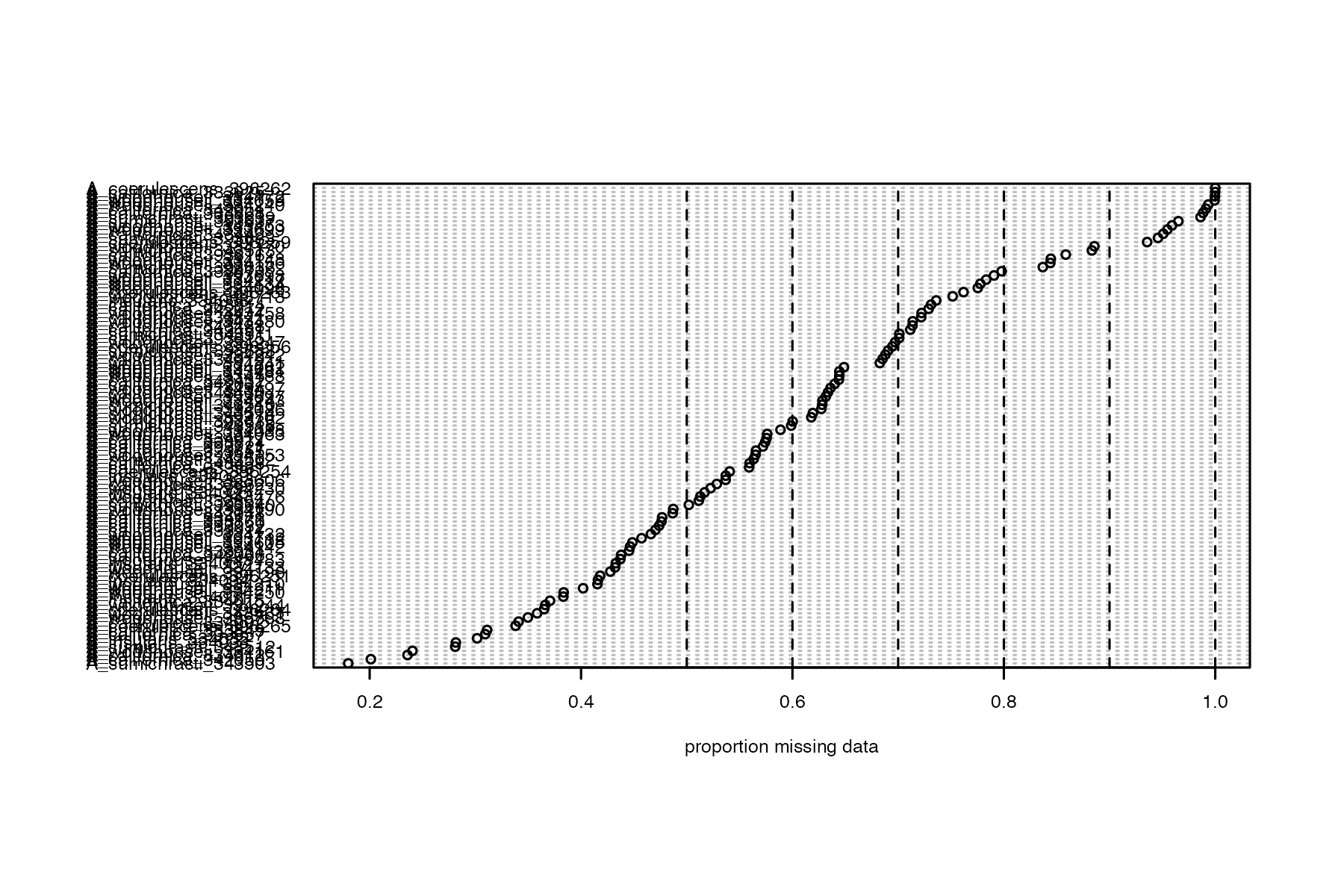
Now we can try setting a reasonable threshold, and then visualizing clustering patterns to determine whether there are still problematic samples with excess missing data that can’t be accurately assigned to genetic clusters
#run function to drop samples above the threshold we want from the vcf
vcfR<-missing_by_sample(vcfR=vcfR, cutoff = .81)
#> 20 samples are above a 0.81 missing data cutoff, and were removed from VCF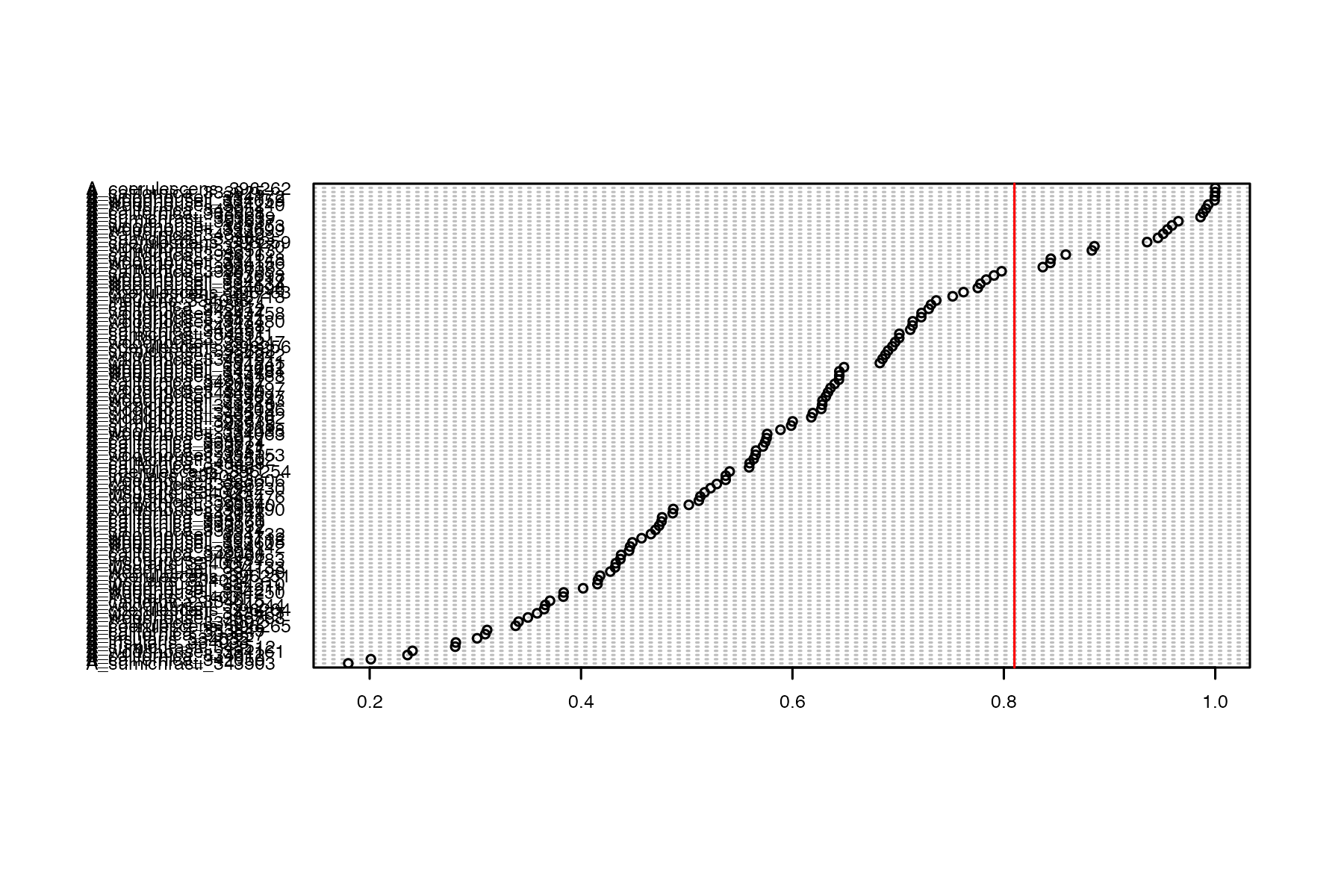
#subset popmap to only include retained individuals
popmap<-popmap[popmap$id %in% colnames(vcfR@gt),]
#remove invariant sites generated by dropping individuals
vcfR<-min_mac(vcfR, min.mac = 1)
#> 0.61% of SNPs fell below a minor allele count of 1 and were removed from the VCF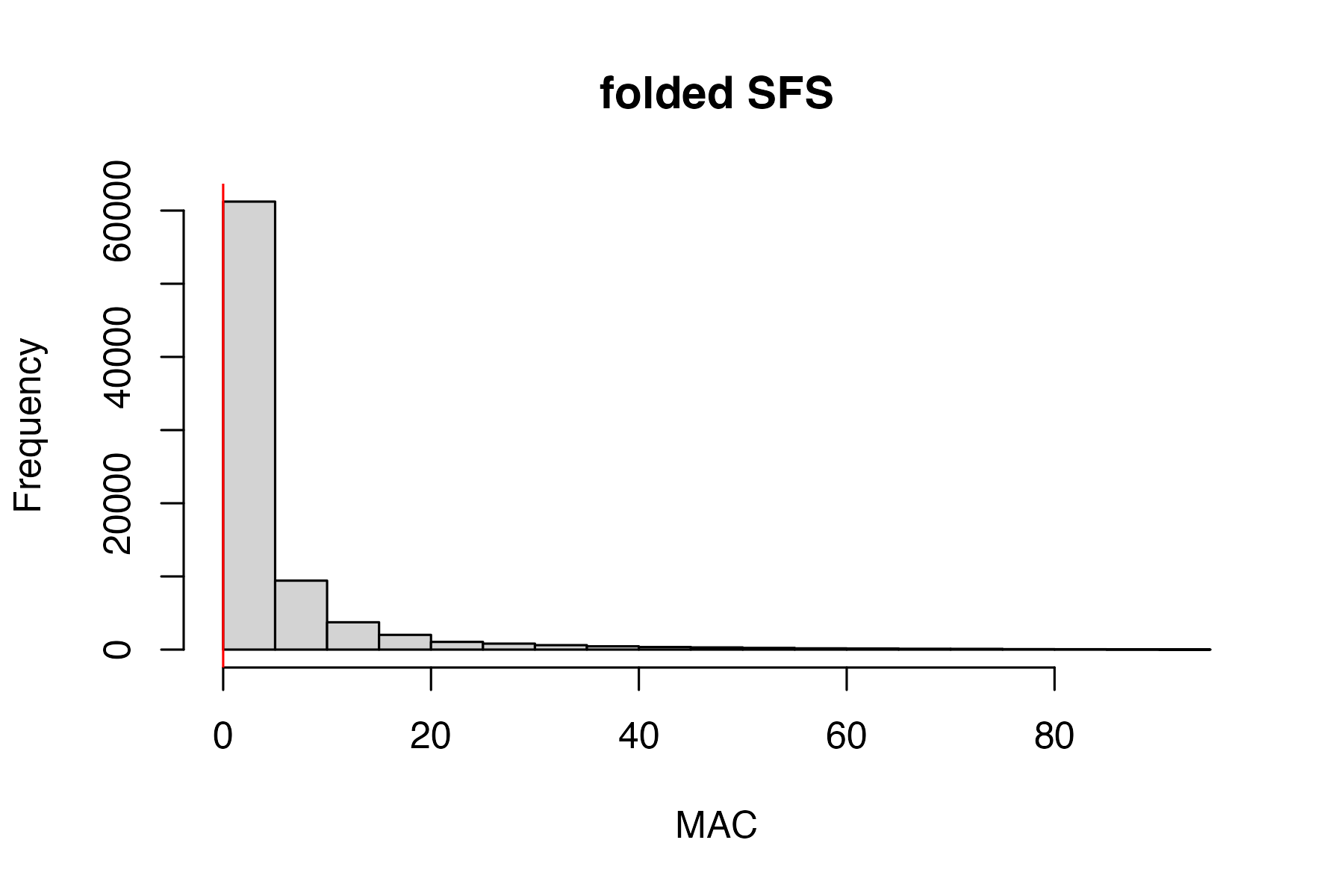
#verify that missing data is not driving clustering patterns among the retained samples
miss<-assess_missing_data_pca(vcfR=vcfR, popmap = popmap, thresholds = .8, clustering = FALSE)
#> cutoff is specified, filtered vcfR object will be returned
#> 76.56% of SNPs fell below a completeness cutoff of 0.8 and were removed from the VCF
#> Loading required namespace: adegenet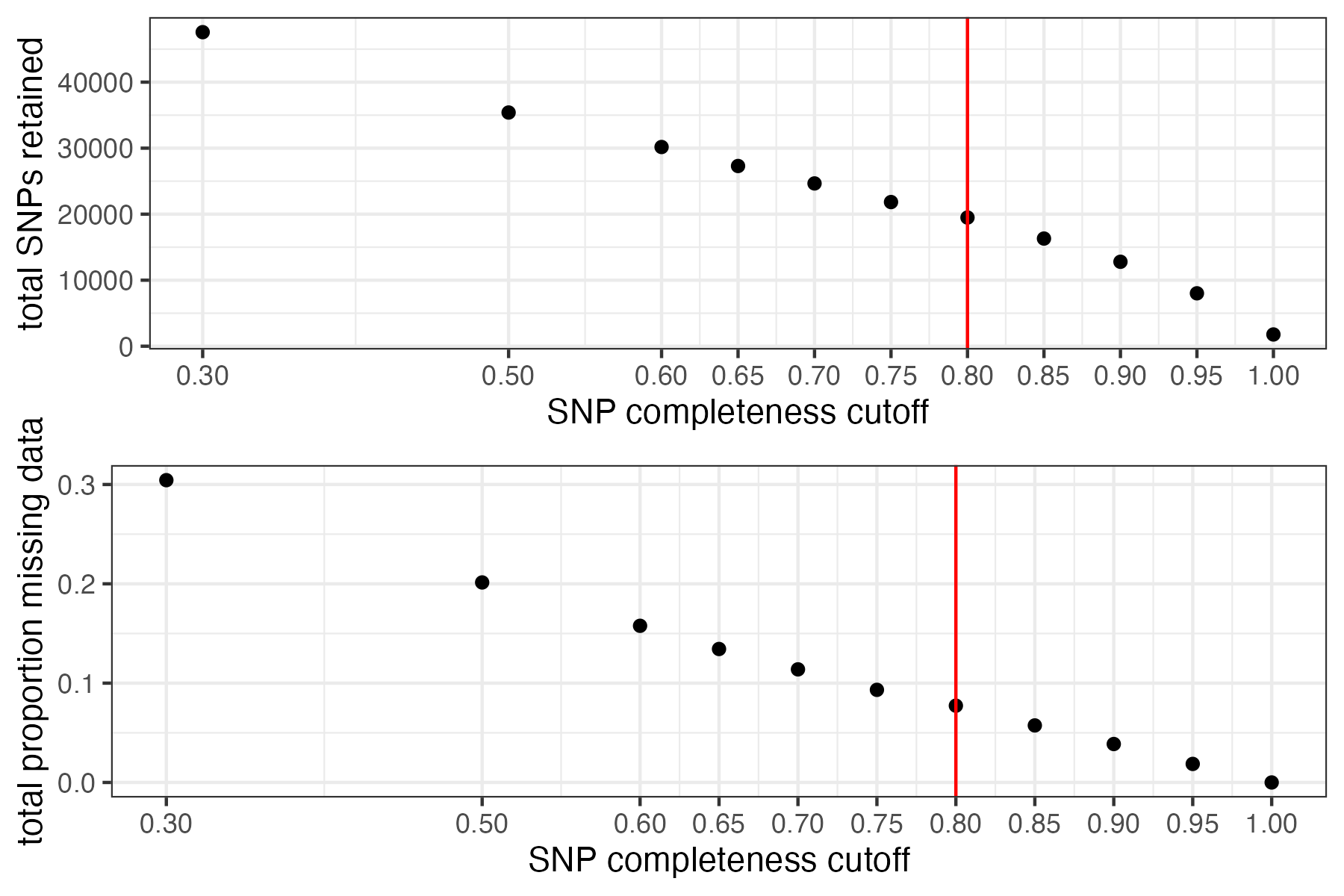
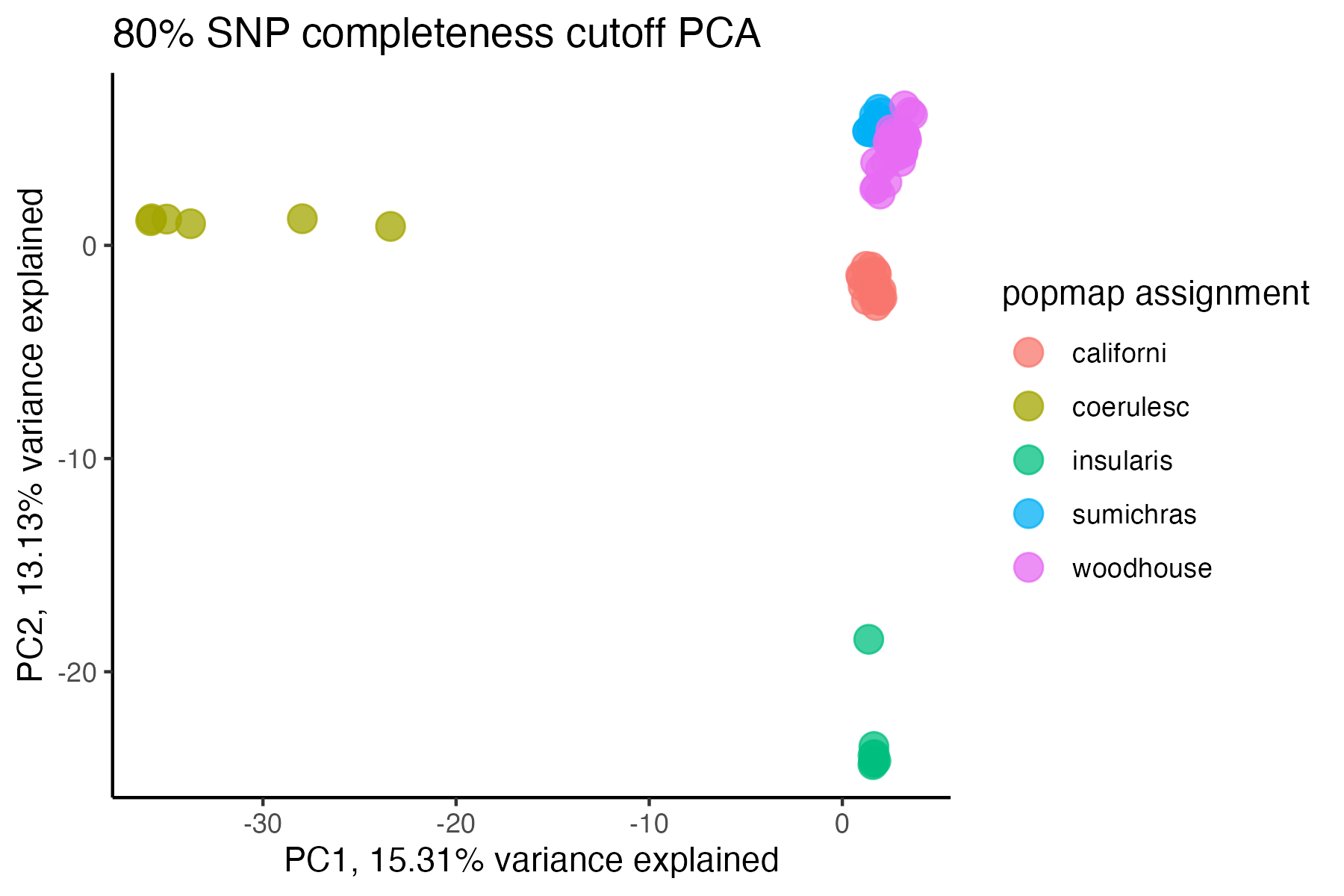
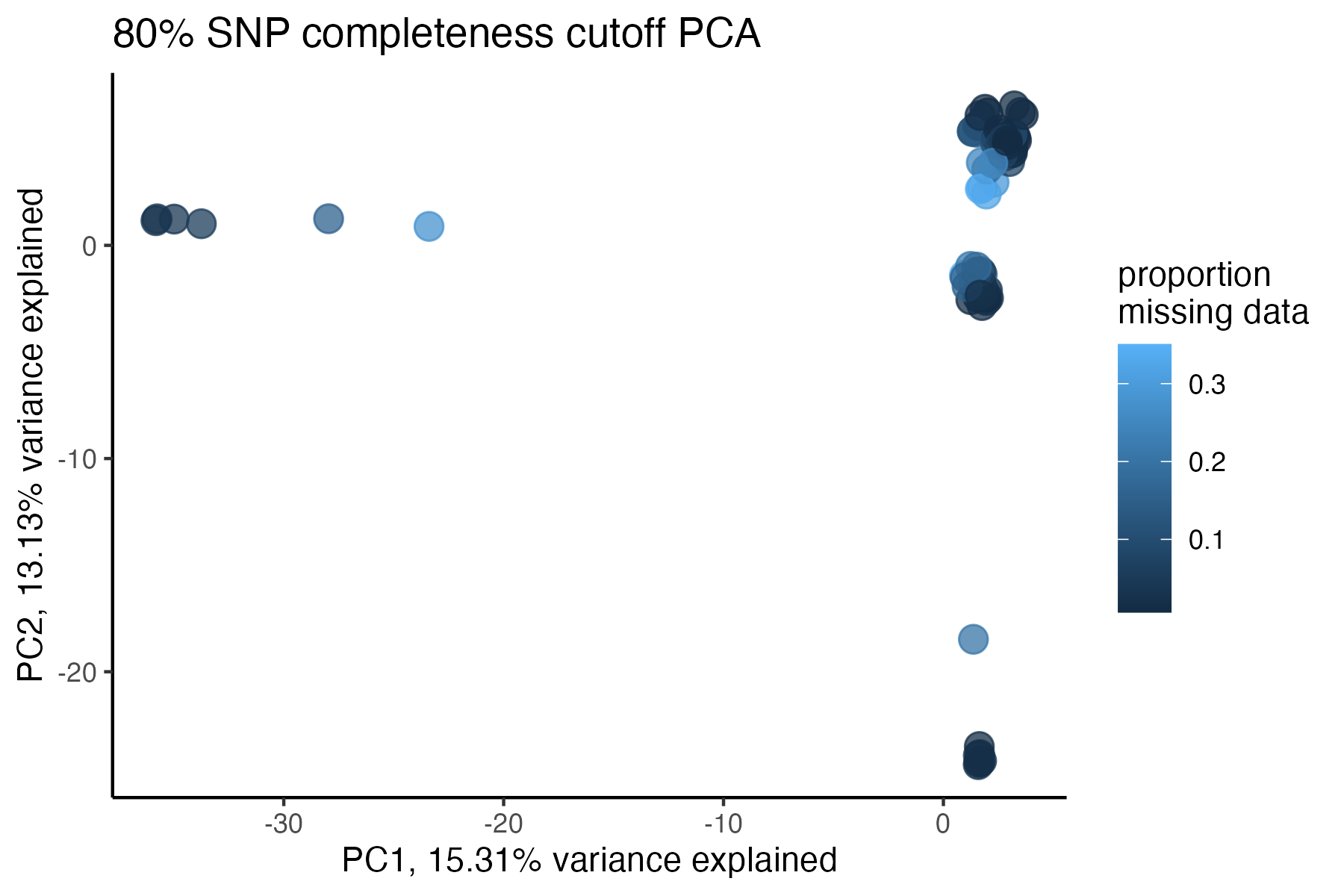
#if there are still problematic samples, drop them using the following syntax
#vcfR <- vcfR[,colnames(vcfR@gt) != "A_woodhouseii_24711" & colnames(vcfR@gt) != "A_californica_45901"]Step 4: set missing data per SNP cutoff
Note:
This filter interacts with the above filter, where we dropped low data samples. A good rule of thumb is that individual samples shouldn’t be above 50% missing data after applying a per-SNP missing data cutoff. So if we are retaining specific low data samples out of necessity or project design, we may have to set a more stringent per-SNP missing data cutoff, at the expense of the total number of SNPs retained for downstream analyses. We can again use the assess_missing_data_pca() function to determine whether all retained samples contain enough data at our chosen cutoff in order to be assigned accurately to their species group.
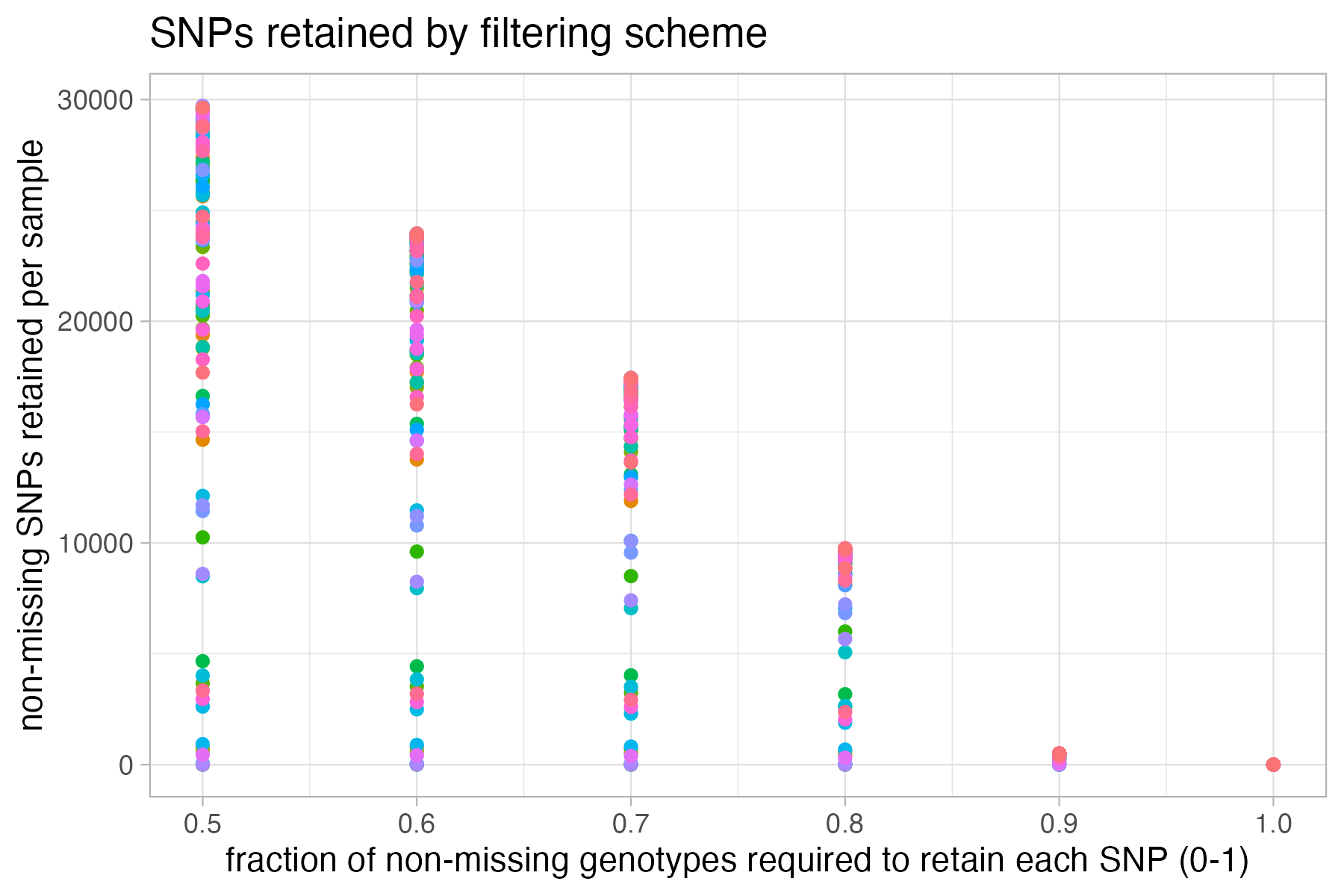
#visualize missing data by SNP and the effect of various cutoffs on the missingness of each sample
missing_by_snp(vcfR)
#> cutoff is not specified, exploratory visualizations will be generated
#> Picking joint bandwidth of 0.0645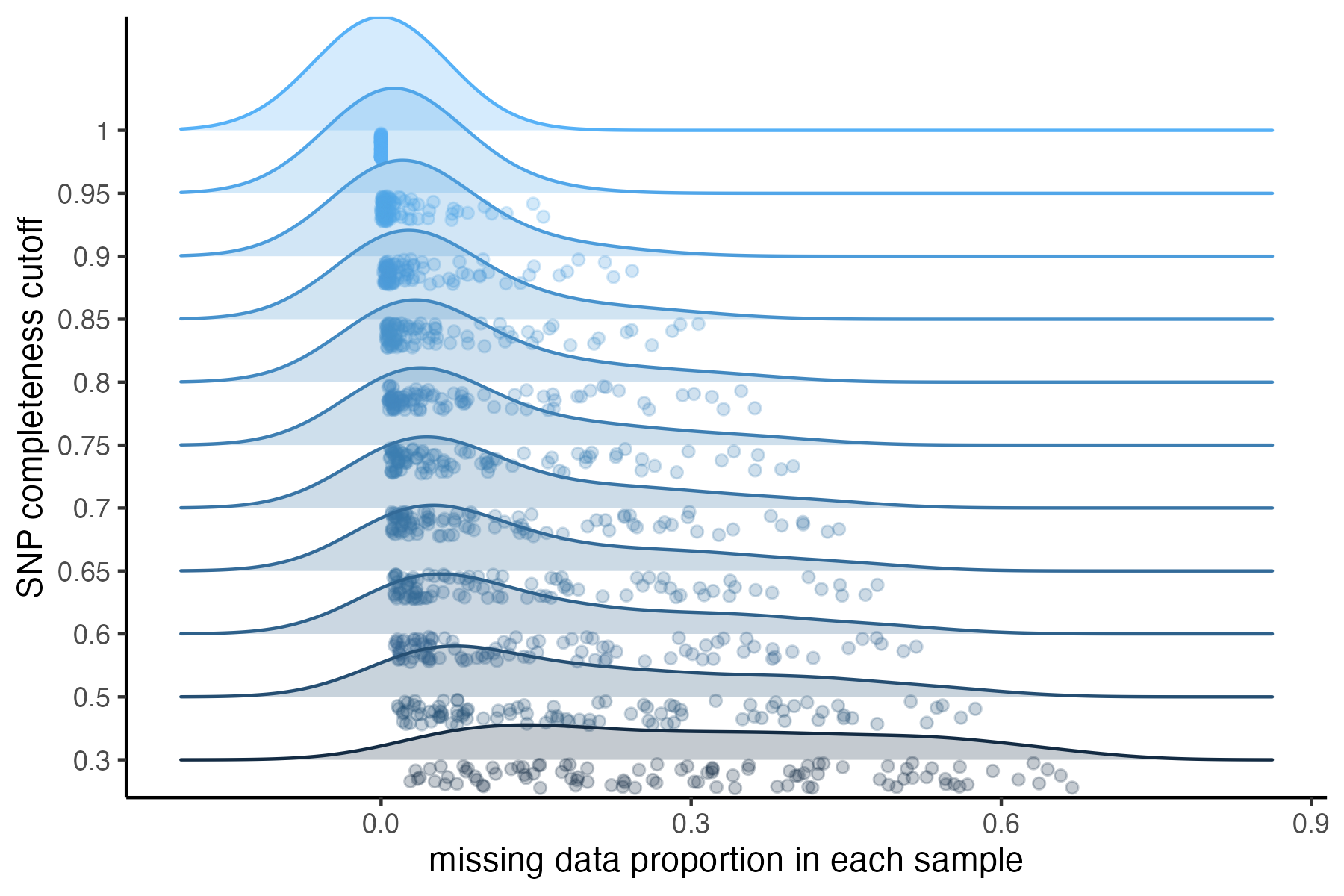
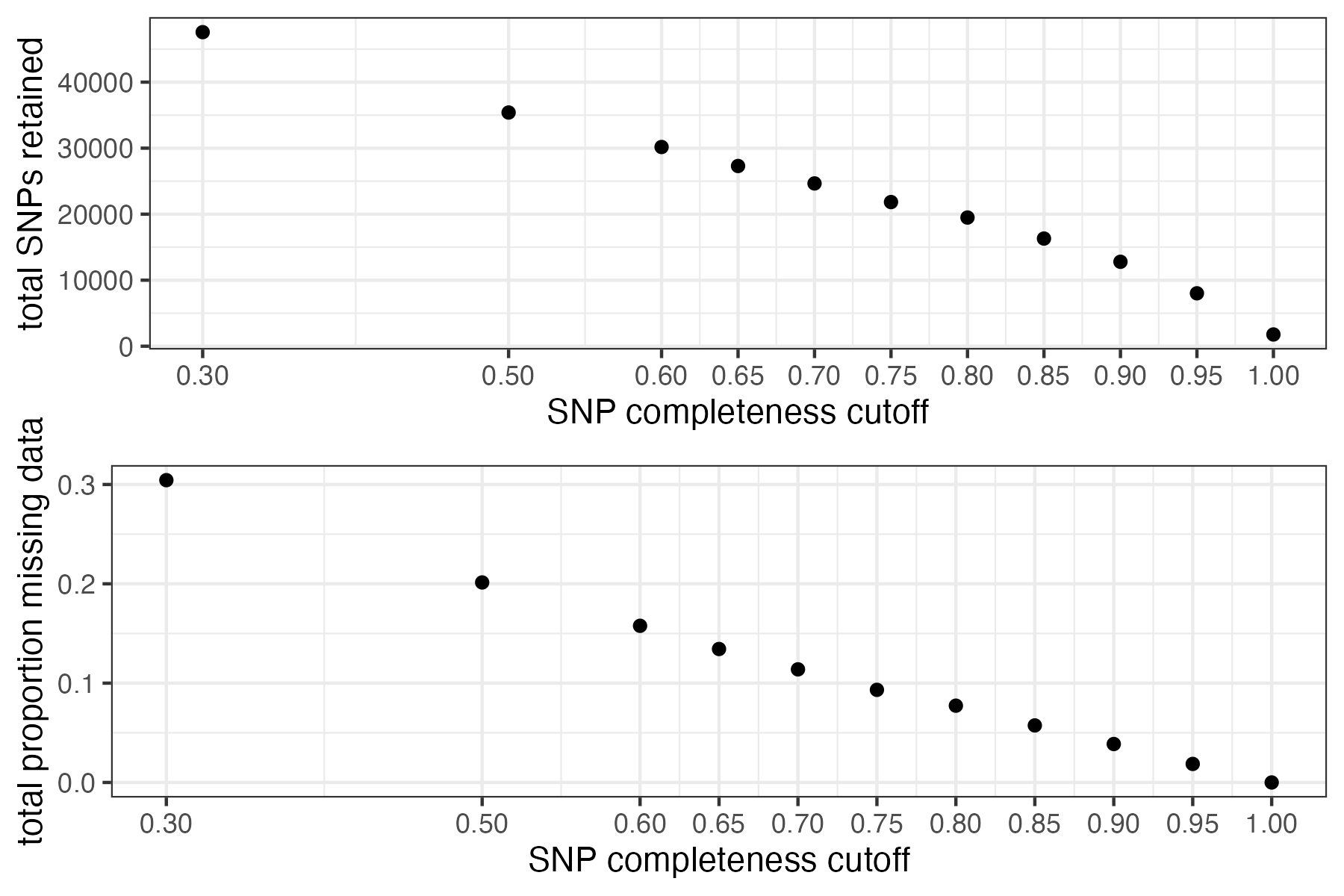
#> filt missingness snps.retained
#> 1 0.30 0.30436210 47570
#> 2 0.50 0.20138396 35398
#> 3 0.60 0.15772868 30174
#> 4 0.65 0.13437846 27298
#> 5 0.70 0.11387863 24657
#> 6 0.75 0.09326028 21836
#> 7 0.80 0.07731504 19491
#> 8 0.85 0.05743029 16307
#> 9 0.90 0.03871199 12790
#> 10 0.95 0.01867360 8013
#> 11 1.00 0.00000000 1779
#check if these cutoffs prevent samples from clustering
#by patterns of missing data in a PCA
miss<-assess_missing_data_pca(vcfR=vcfR, popmap = popmap,
thresholds = c(.75,.85,.95), clustering = FALSE)
#> cutoff is specified, filtered vcfR object will be returned
#> 72.84% of SNPs fell below a completeness cutoff of 0.75 and were removed from the VCF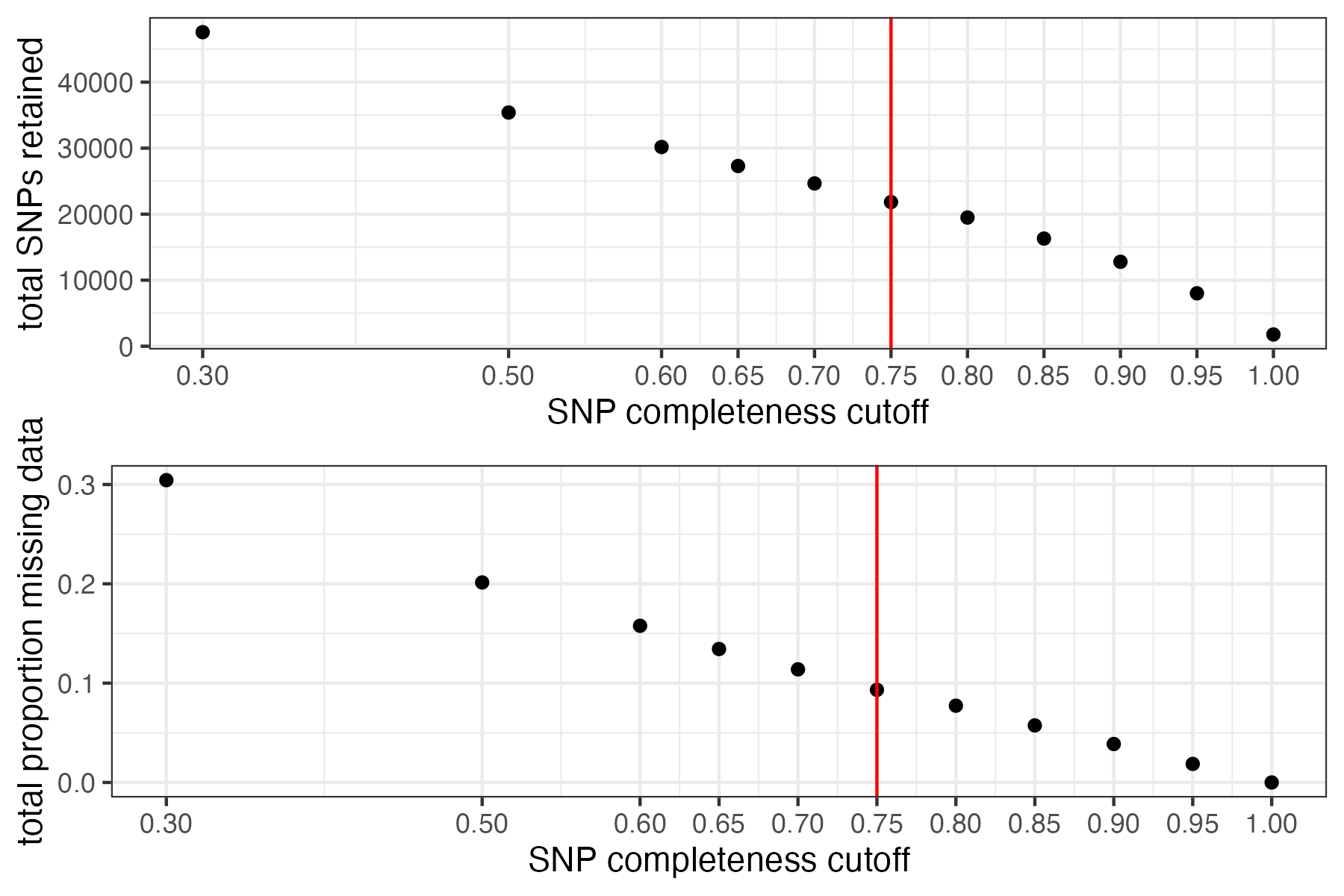
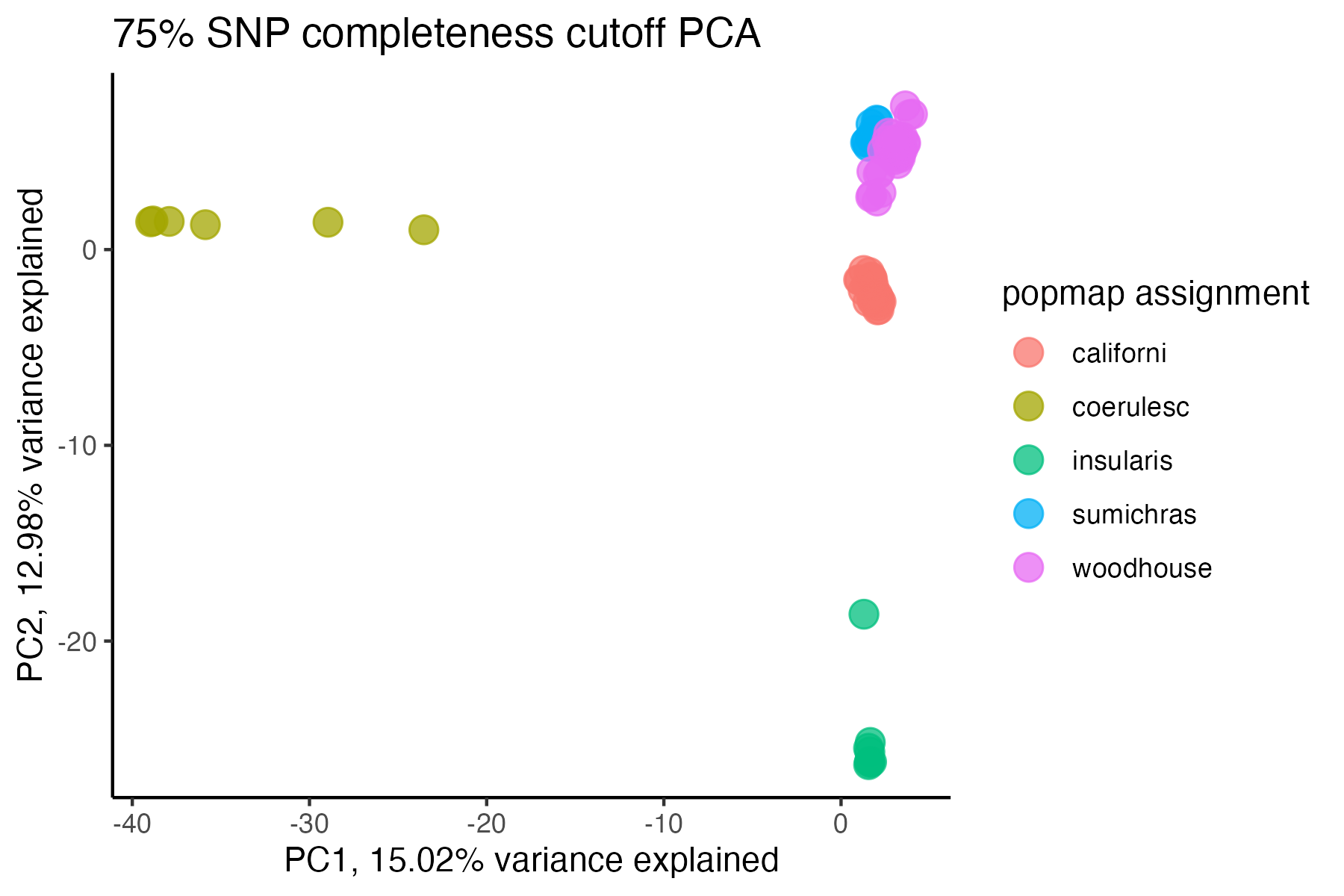
#> cutoff is specified, filtered vcfR object will be returned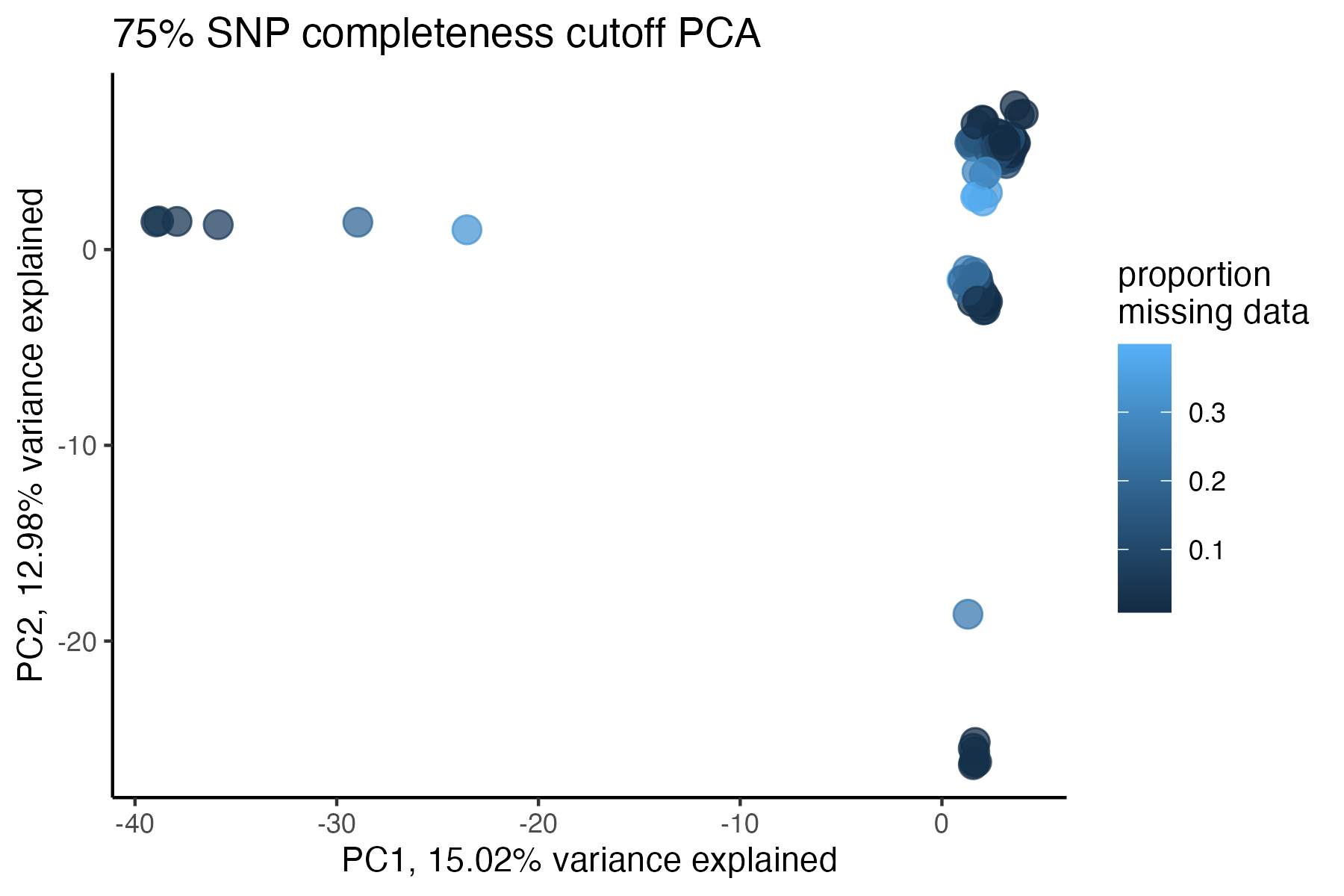
#> 79.72% of SNPs fell below a completeness cutoff of 0.85 and were removed from the VCF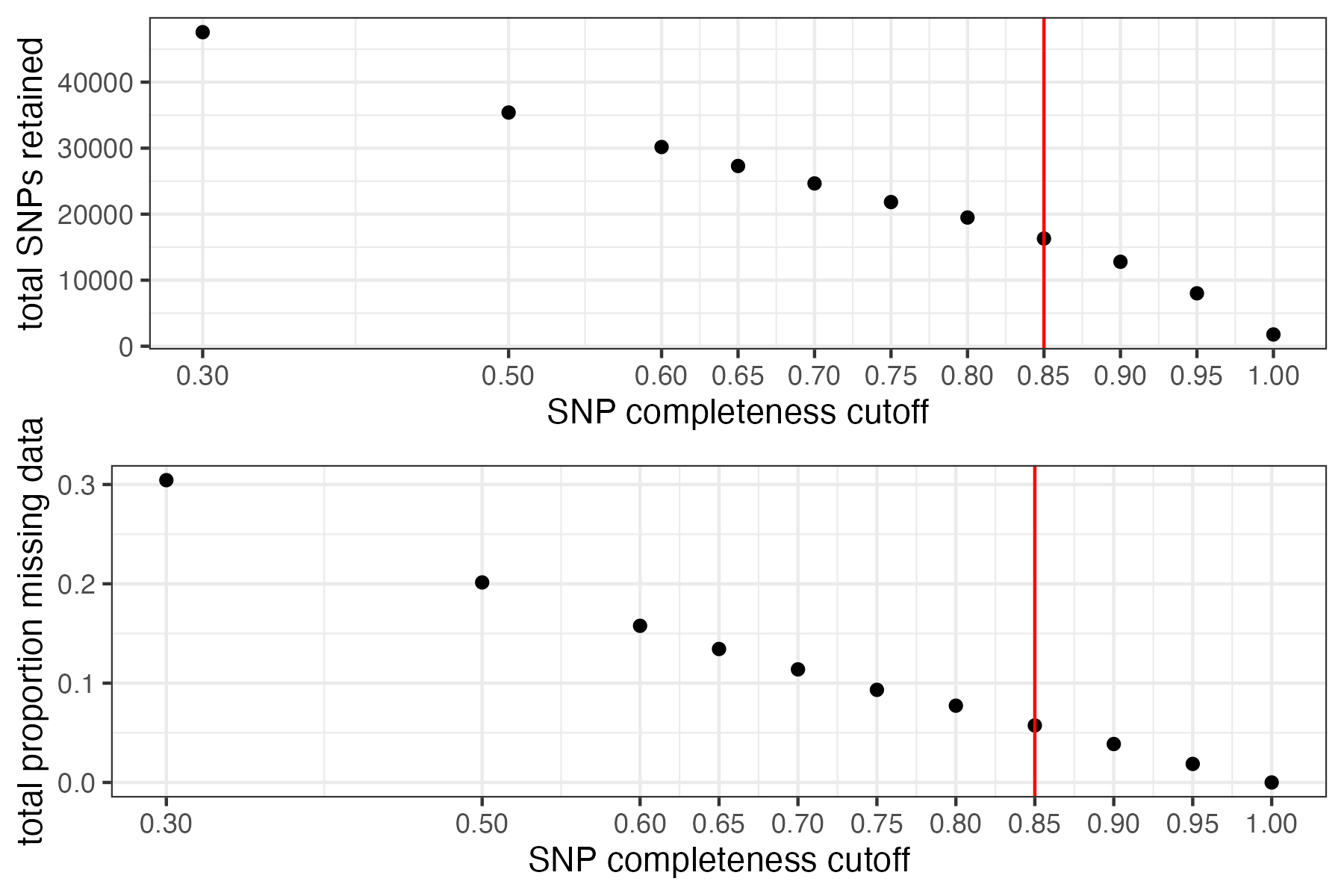
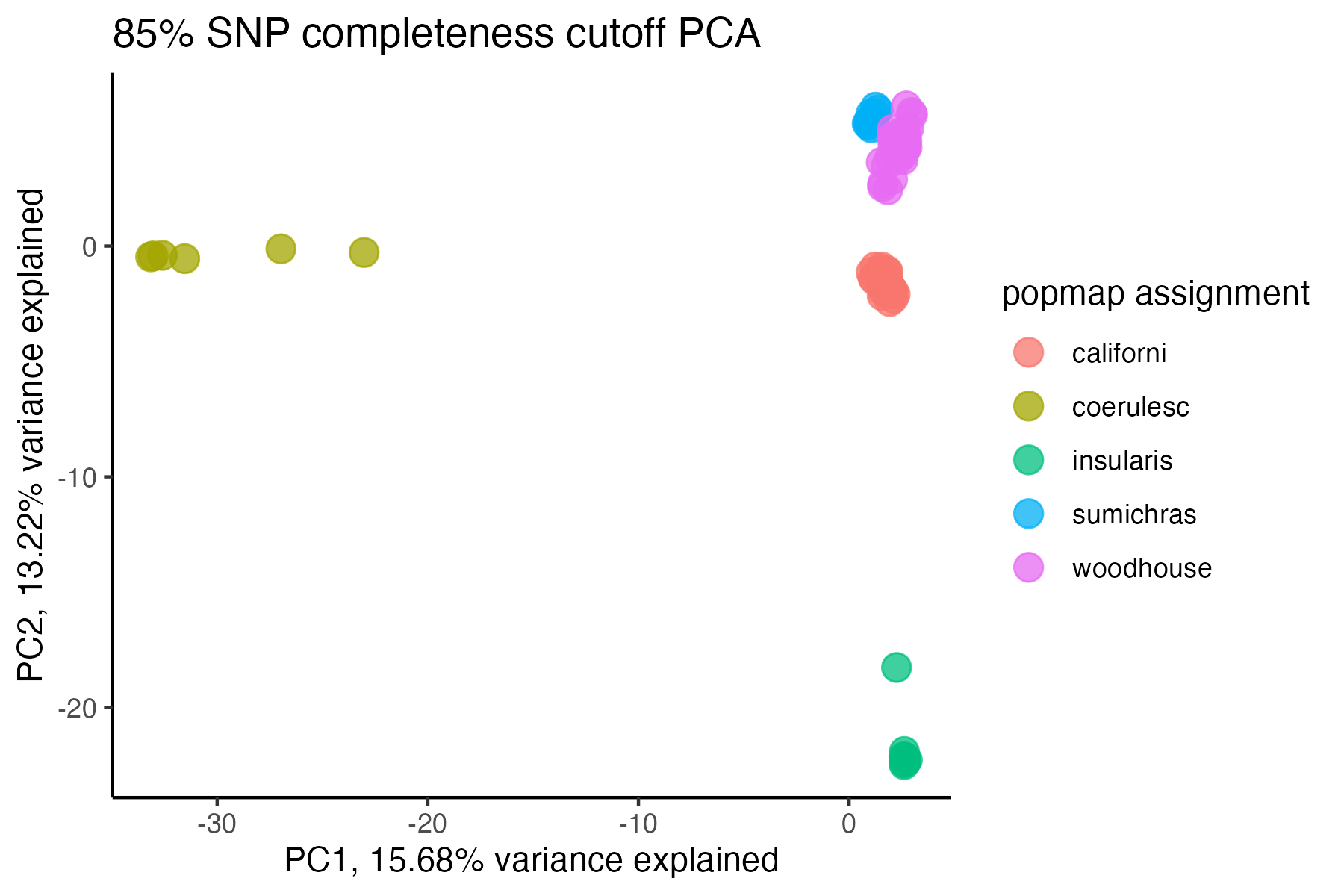
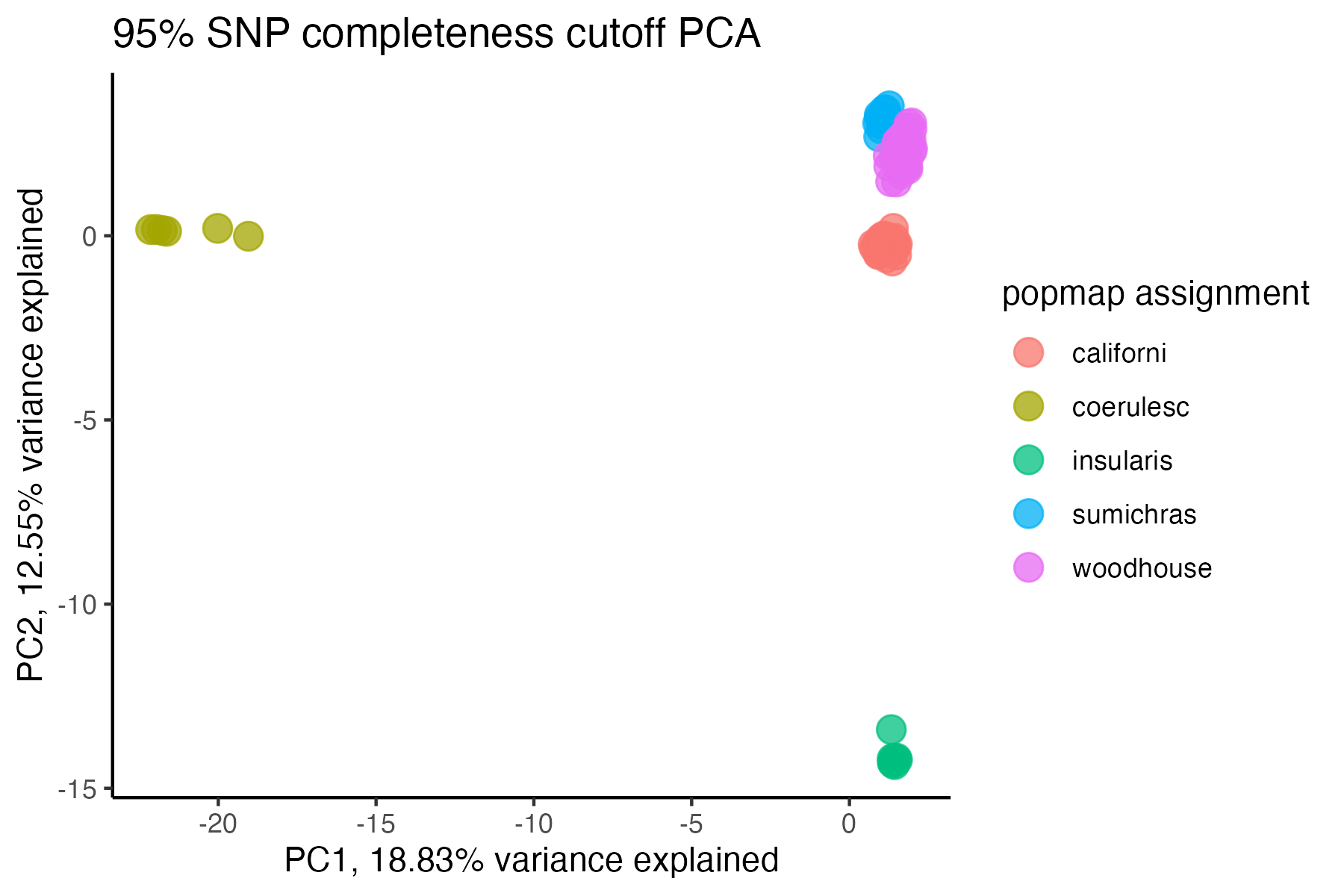
#> cutoff is specified, filtered vcfR object will be returned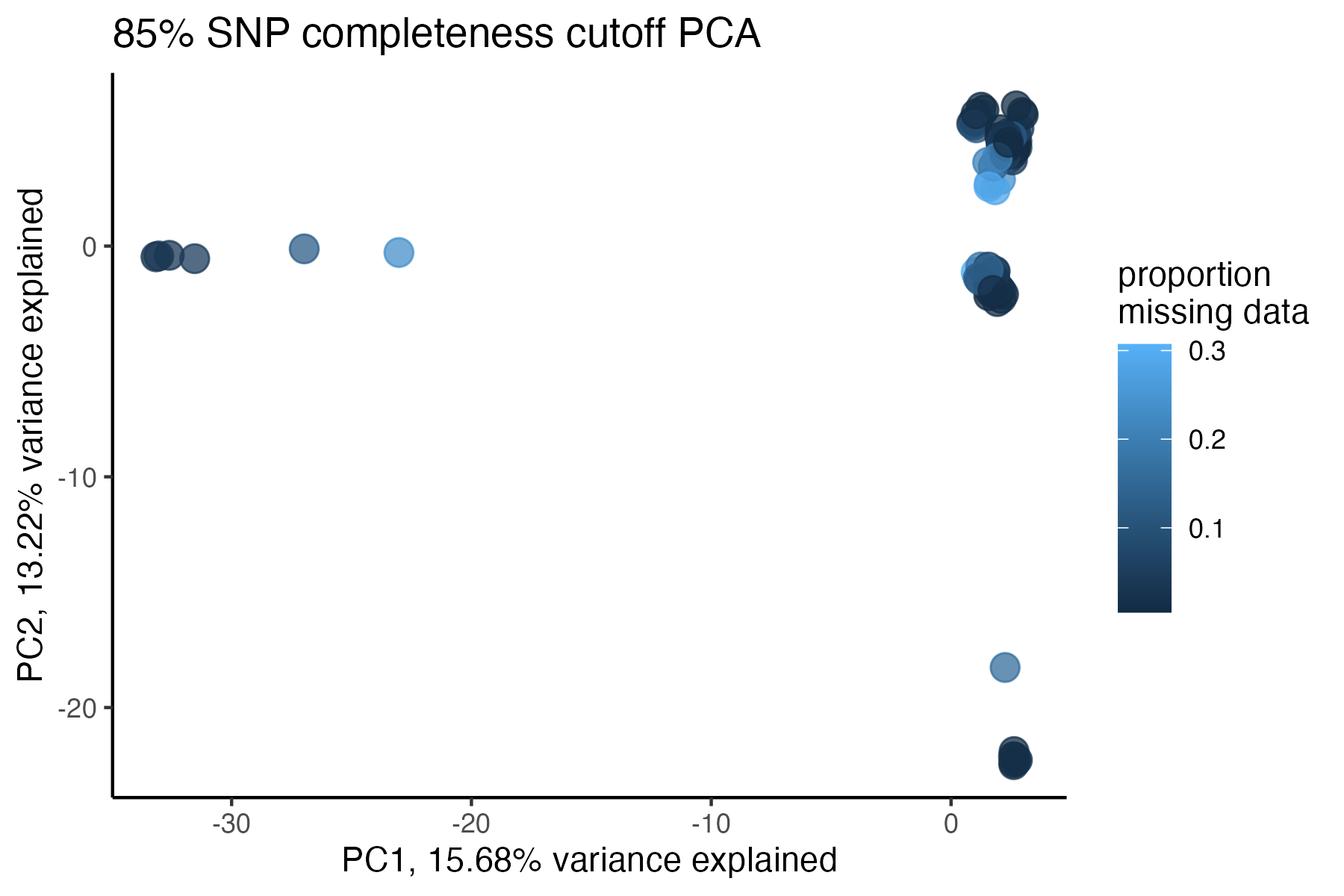
#> 90.03% of SNPs fell below a completeness cutoff of 0.95 and were removed from the VCF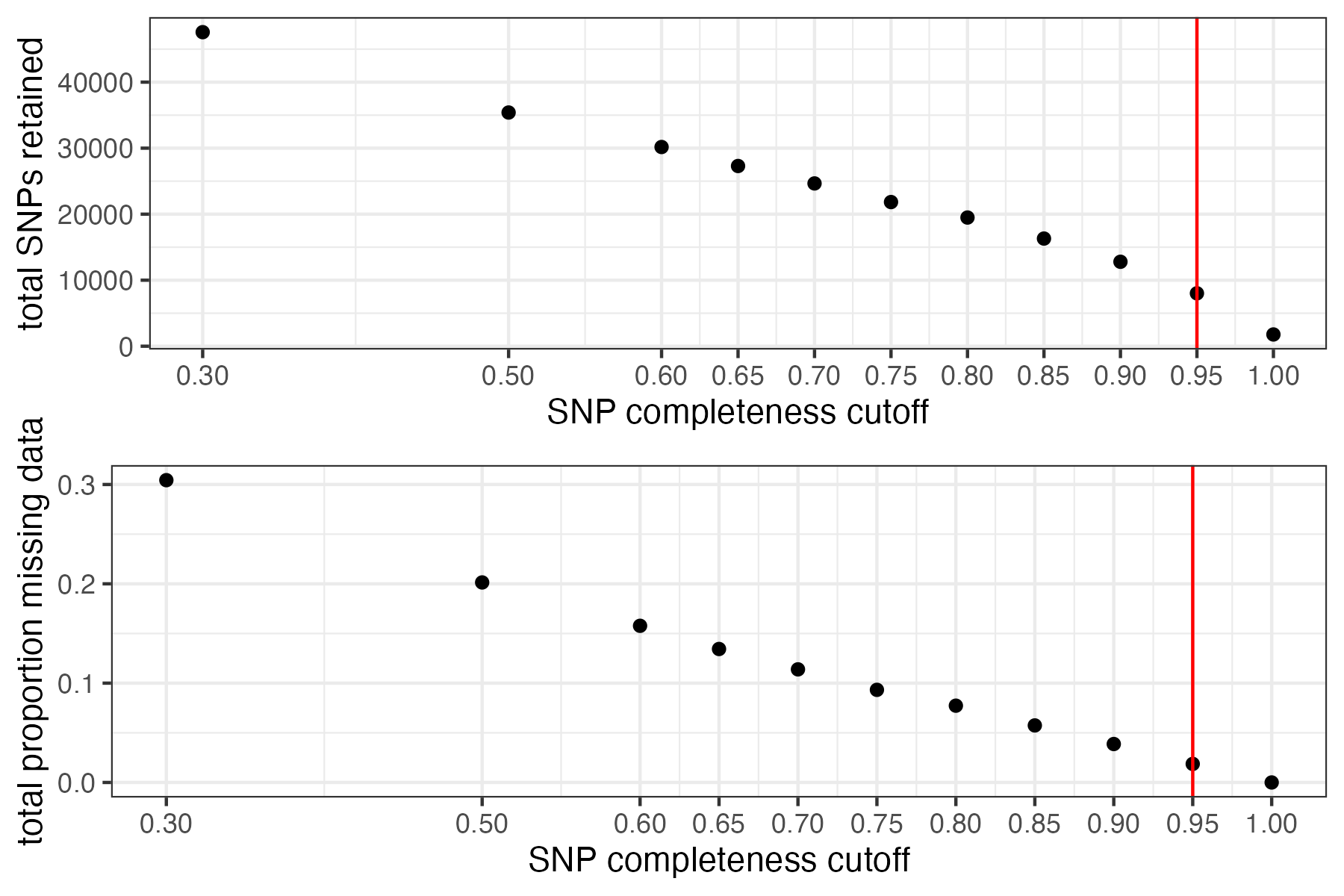
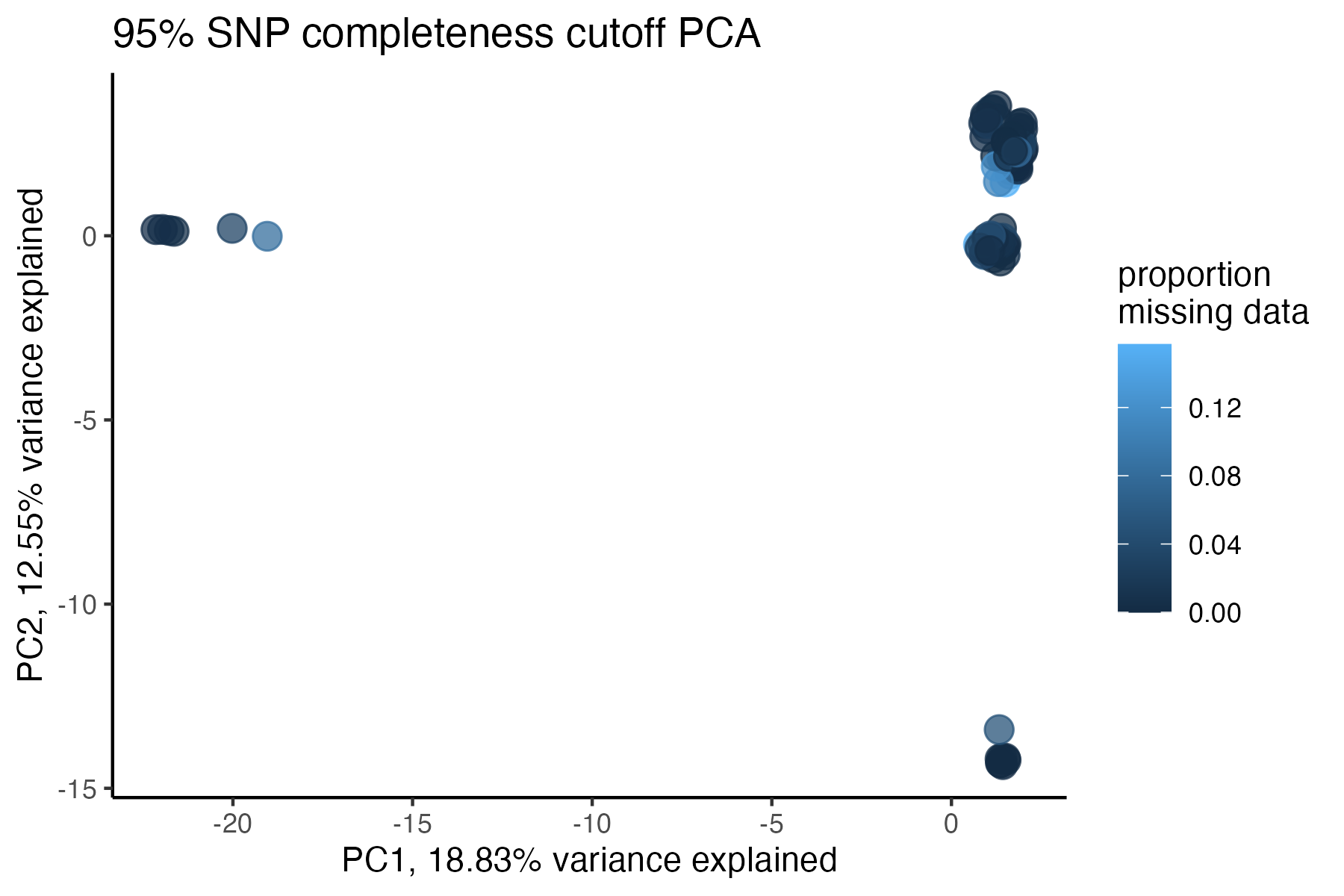
#check what t-SNE clustering looks like at an 85% threshold
miss<-assess_missing_data_tsne(vcfR=vcfR, popmap = popmap,
thresholds = c(.75,.85,.95), clustering = FALSE)
#> cutoff is specified, filtered vcfR object will be returned
#> 72.84% of SNPs fell below a completeness cutoff of 0.75 and were removed from the VCF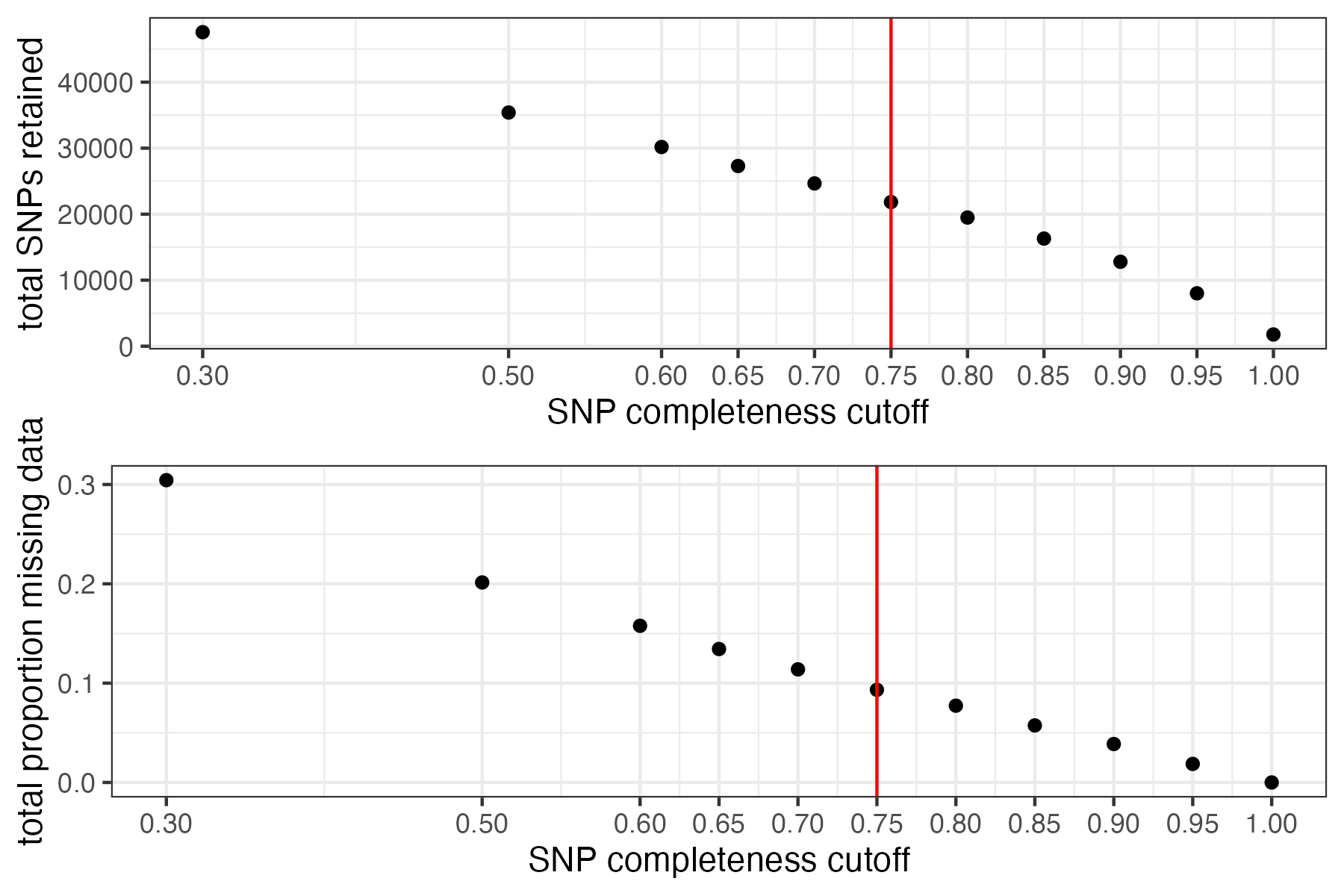
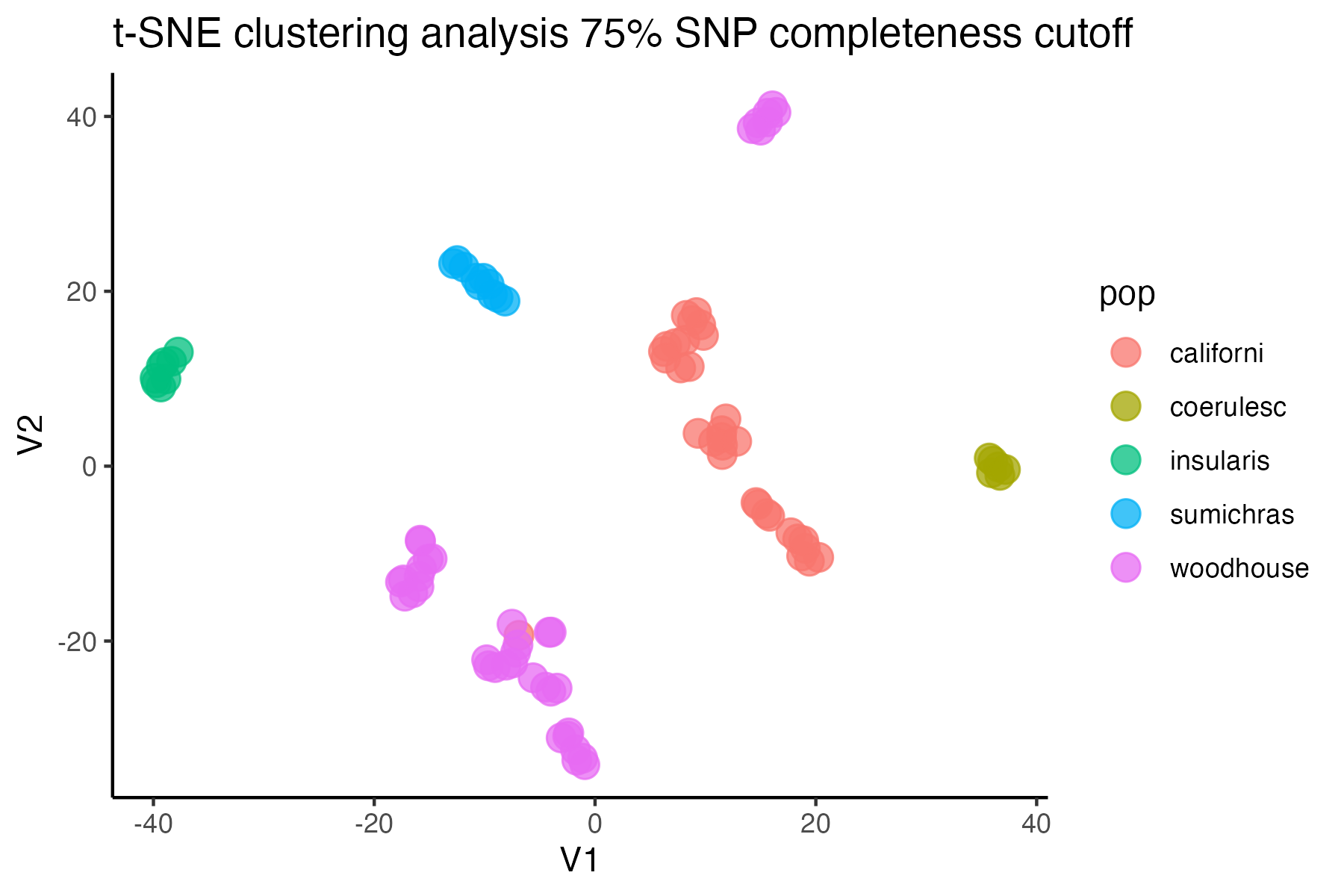
#> cutoff is specified, filtered vcfR object will be returned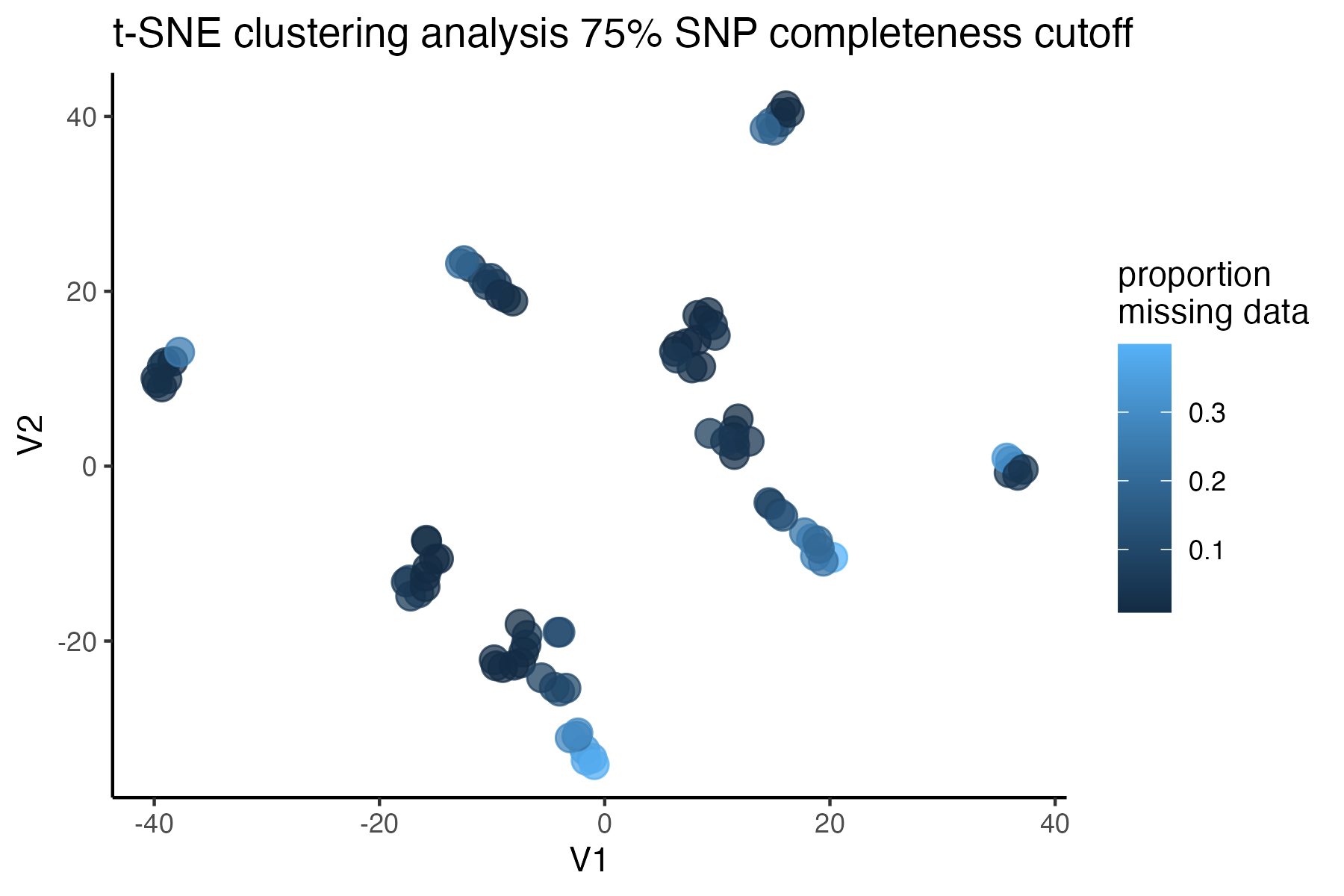
#> 79.72% of SNPs fell below a completeness cutoff of 0.85 and were removed from the VCF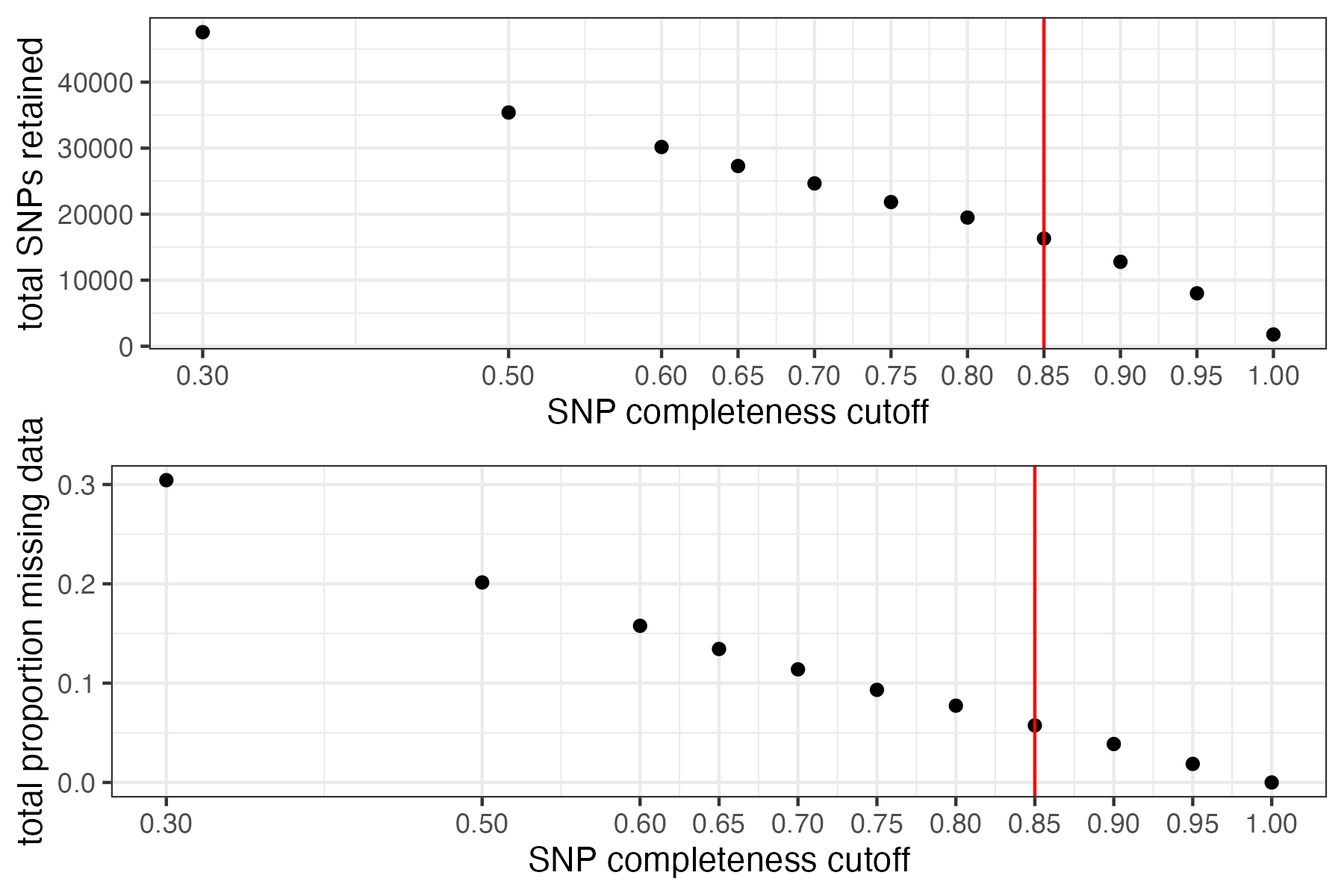
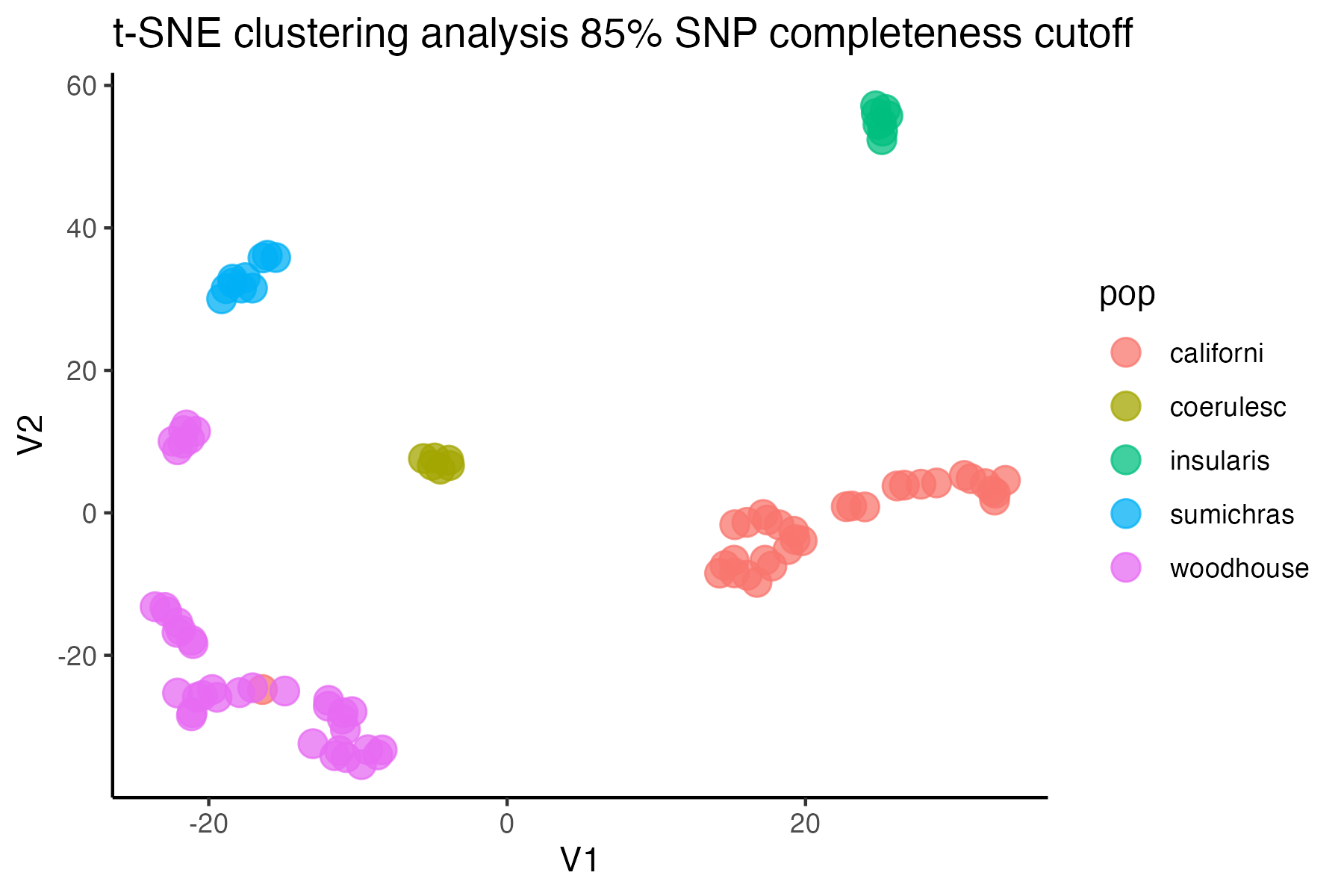
#> cutoff is specified, filtered vcfR object will be returned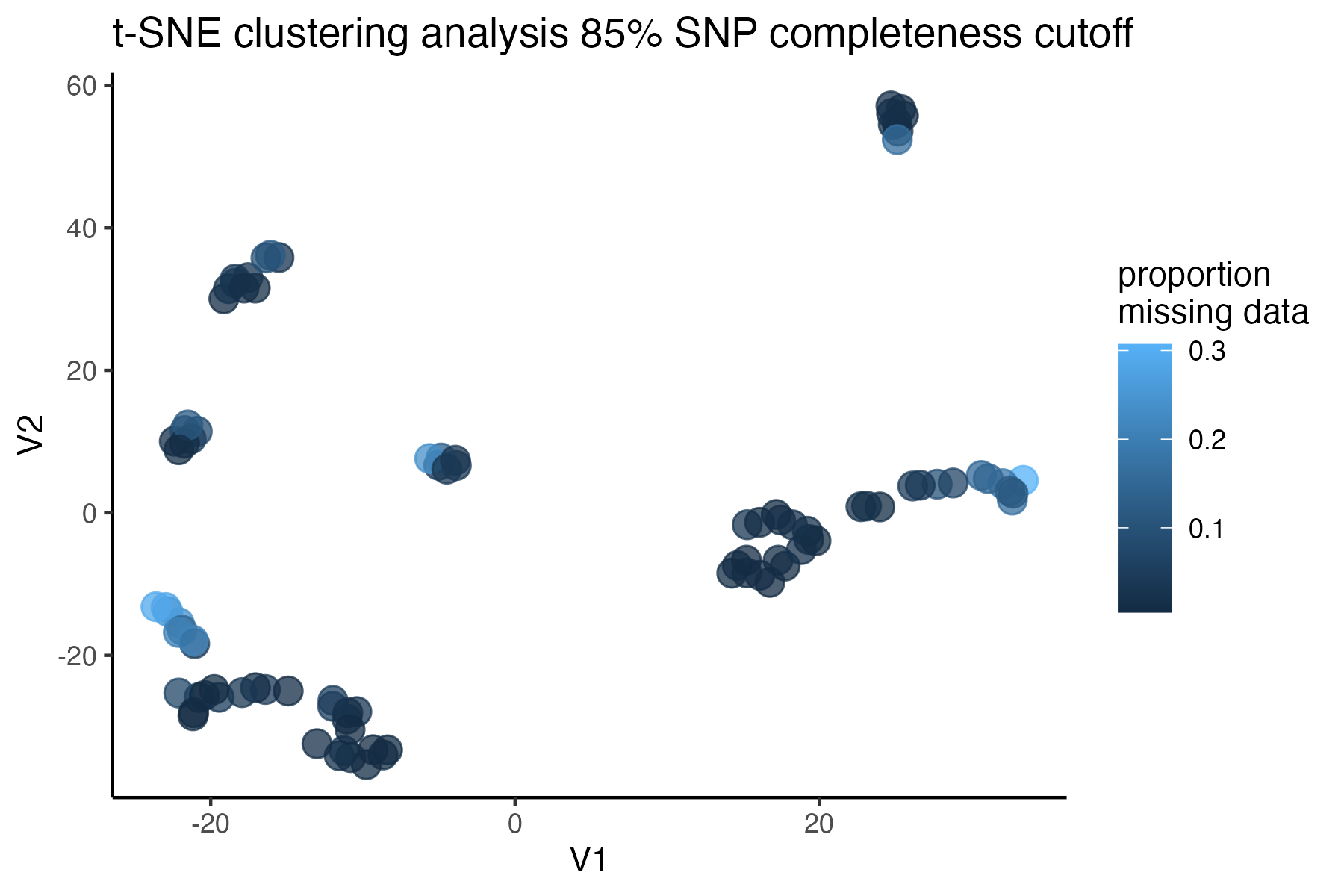
#> 90.03% of SNPs fell below a completeness cutoff of 0.95 and were removed from the VCF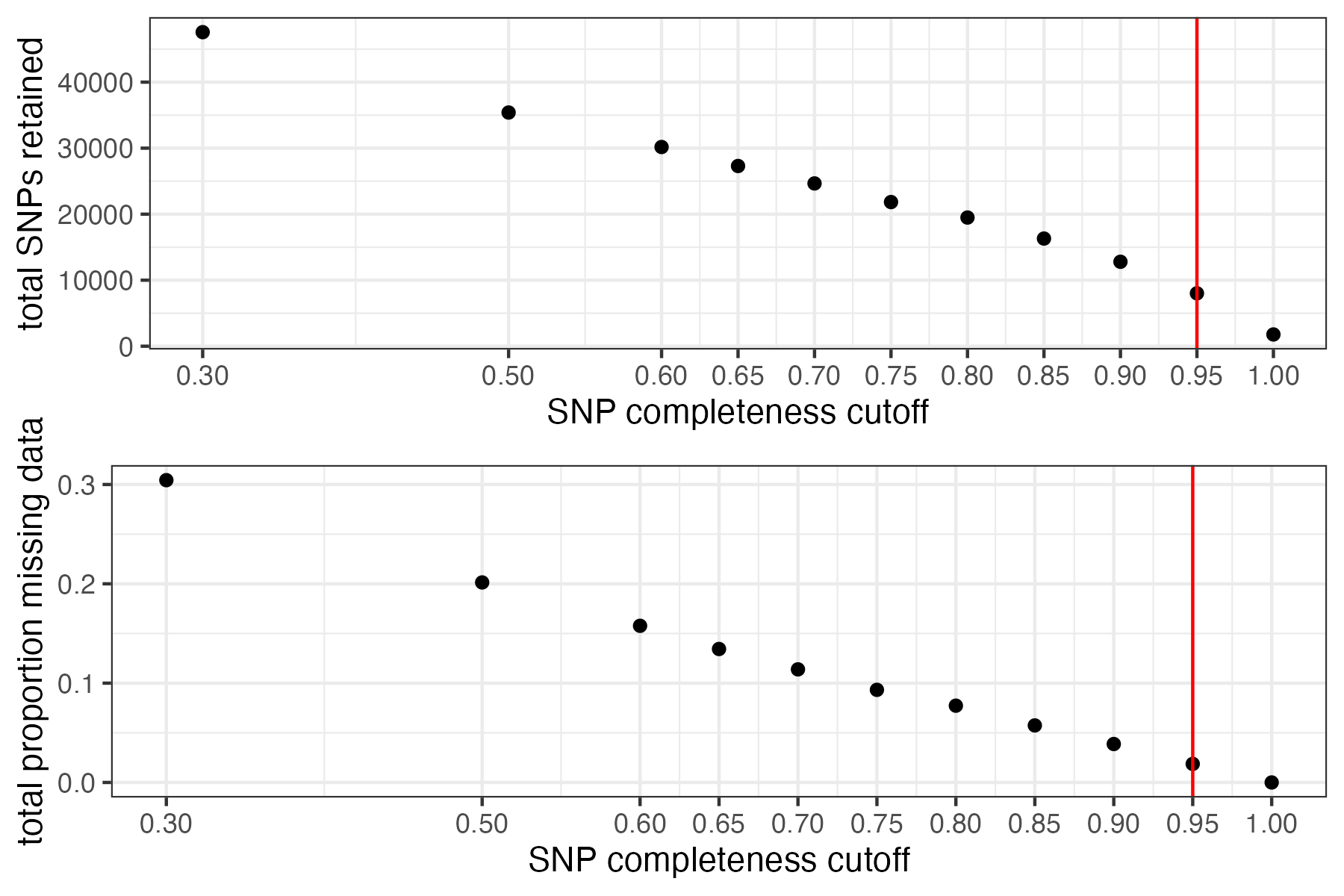
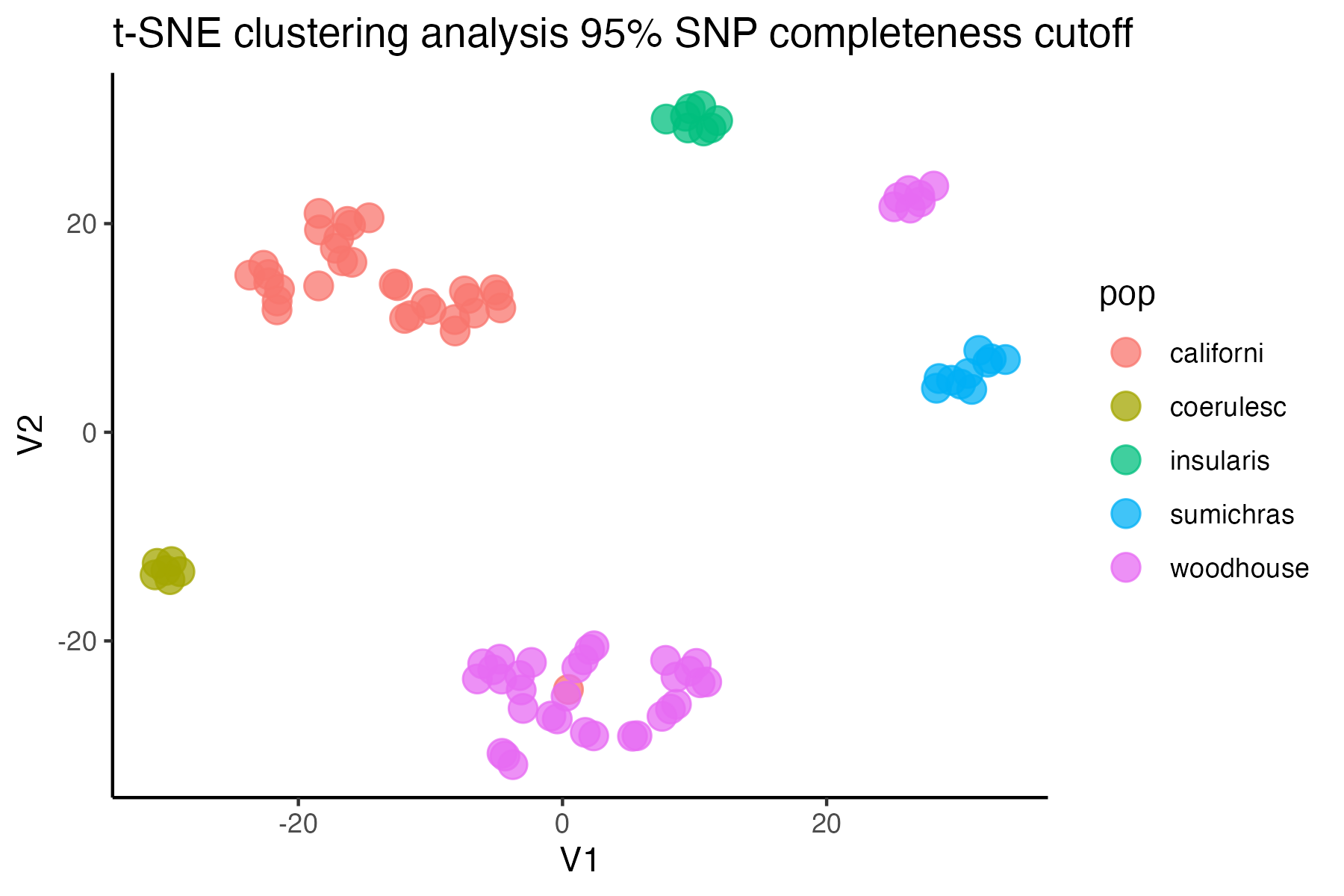
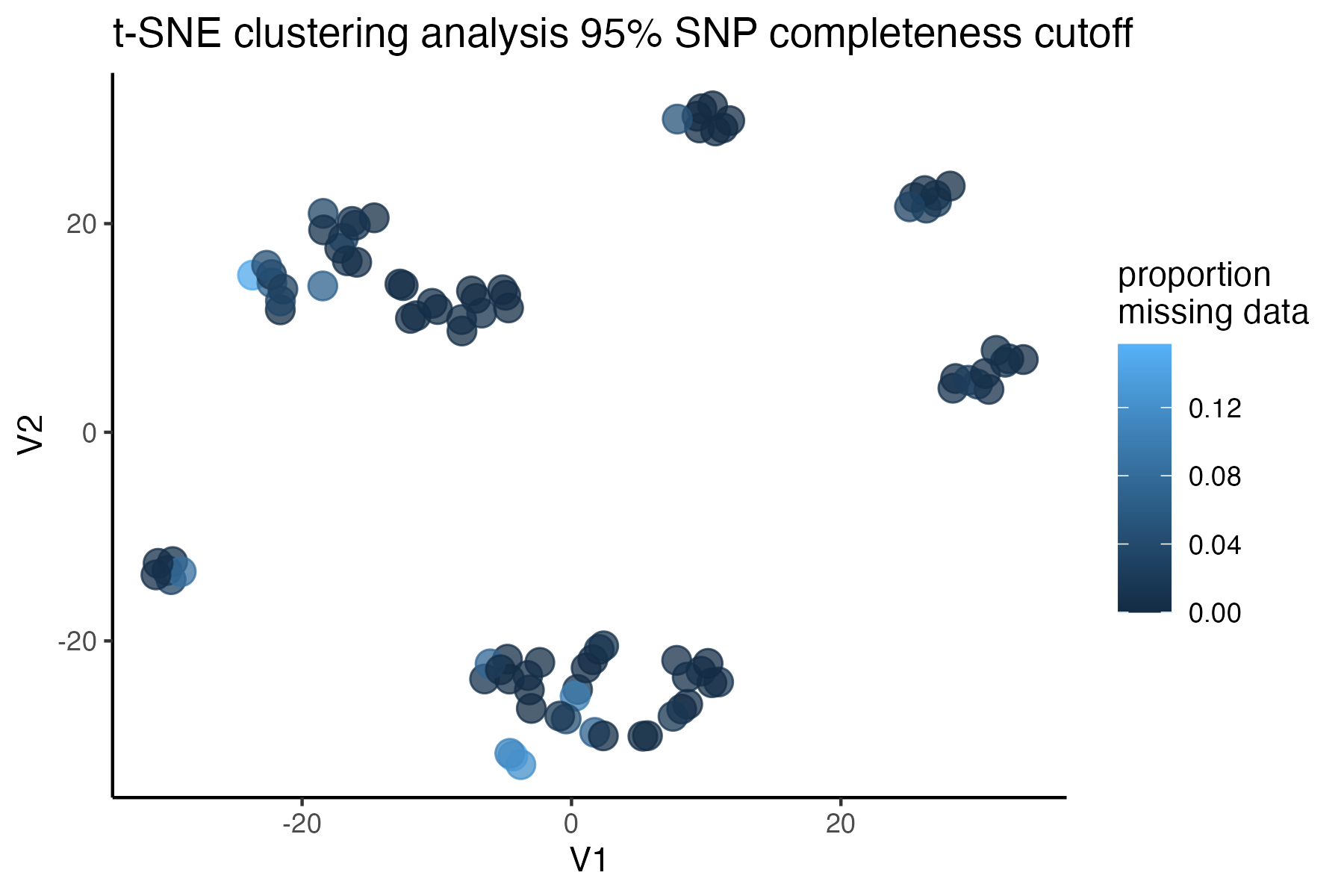
#choose a cutoff resulting in an acceptable amount of missing data in each sample, and maximizes SNPs retained while minimizing overall missing data, and filter vcf
vcfR<-missing_by_snp(vcfR, cutoff = .85)
#> cutoff is specified, filtered vcfR object will be returned
#> 79.72% of SNPs fell below a completeness cutoff of 0.85 and were removed from the VCF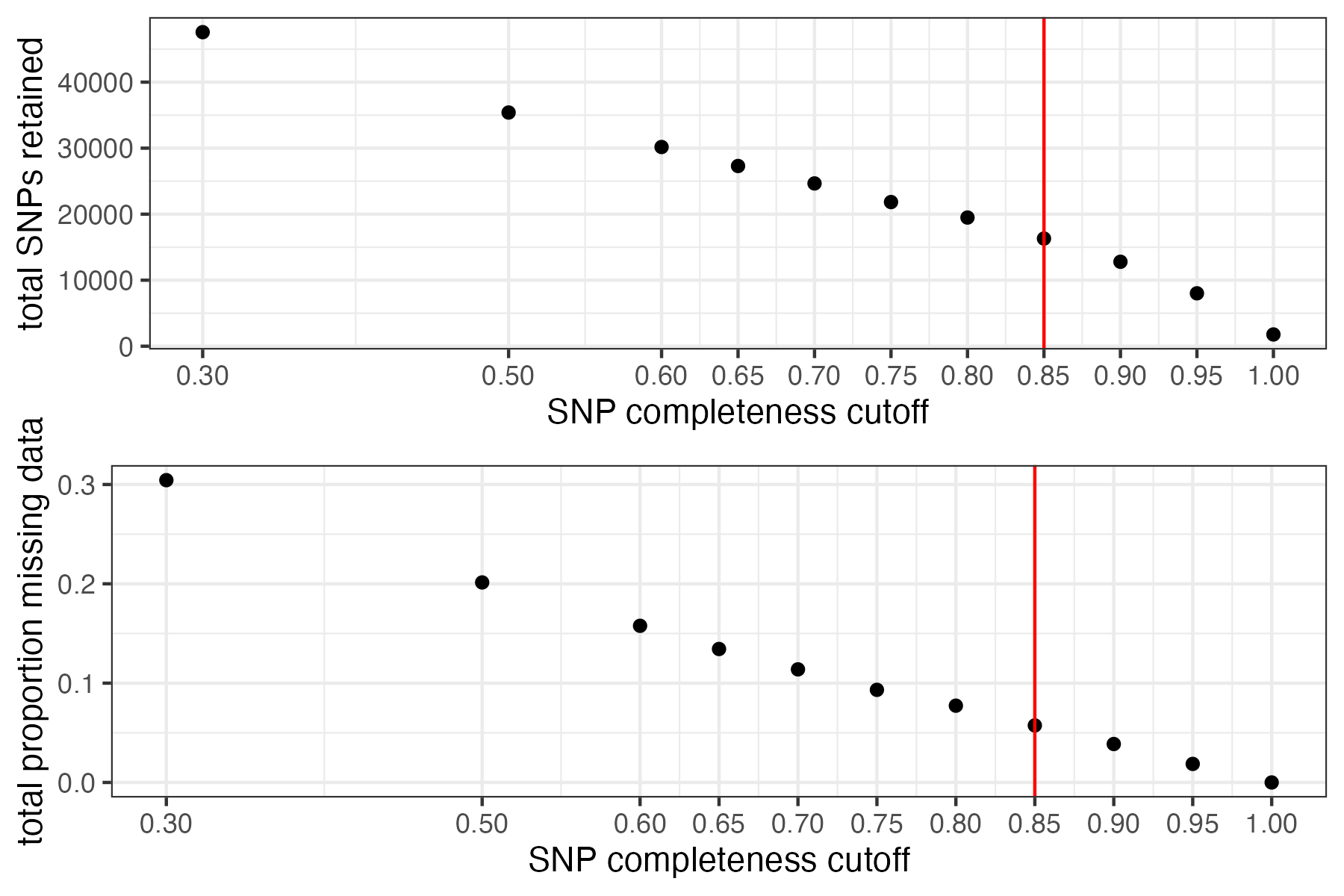
#check how many SNPs and samples are left
vcfR
#> ***** Object of Class vcfR *****
#> 95 samples
#> 36 CHROMs
#> 16,307 variants
#> Object size: 111.2 Mb
#> 5.743 percent missing data
#> ***** ***** *****Step 5: minor allele and linkage filtering
investigate the effect of a minor allele count (MAC) cutoff on downstream inferences. We always want to do this last, because these filters are not quality aware, and using them early in the pipeline will result in dumping good SNPs.
MAC/MAF cutoffs can be helpful in removing spurious and uninformative loci from the dataset, but also have the potential to bias downstream inferences. Linck and Battey (2019) have an excellent paper on just this topic. From the paper-
“We recommend researchers using model‐based programs to describe population structure observe the following best practices: (a) duplicate analyses with nonparametric methods suchas PCA and DAPC with cross validation (b) exclude singletons (c) compare alignments with multiple assembly parameters When seeking to exclude only singletons in alignments with missing data (a ubiquitous problem for reduced‐representation library preparation methods), it is preferable to filter by the count (rather than frequency) of the minor allele, because variation in the amount of missing data across an alignment will cause a static frequency cutoff to remove different SFS classes at different sites”
Our package contains a convenient wrapper functions that can filter based on minor allele count (MAC) and streamline investigation of the effects of various filtering parameters on sample clustering patterns.
#investigate clustering patterns with and without a minor allele cutoff
#use min.mac() to investigate the effect of multiple cutoffs
vcfR.mac<-min_mac(vcfR = vcfR, min.mac = 2)
#> 30.87% of SNPs fell below a minor allele count of 2 and were removed from the VCF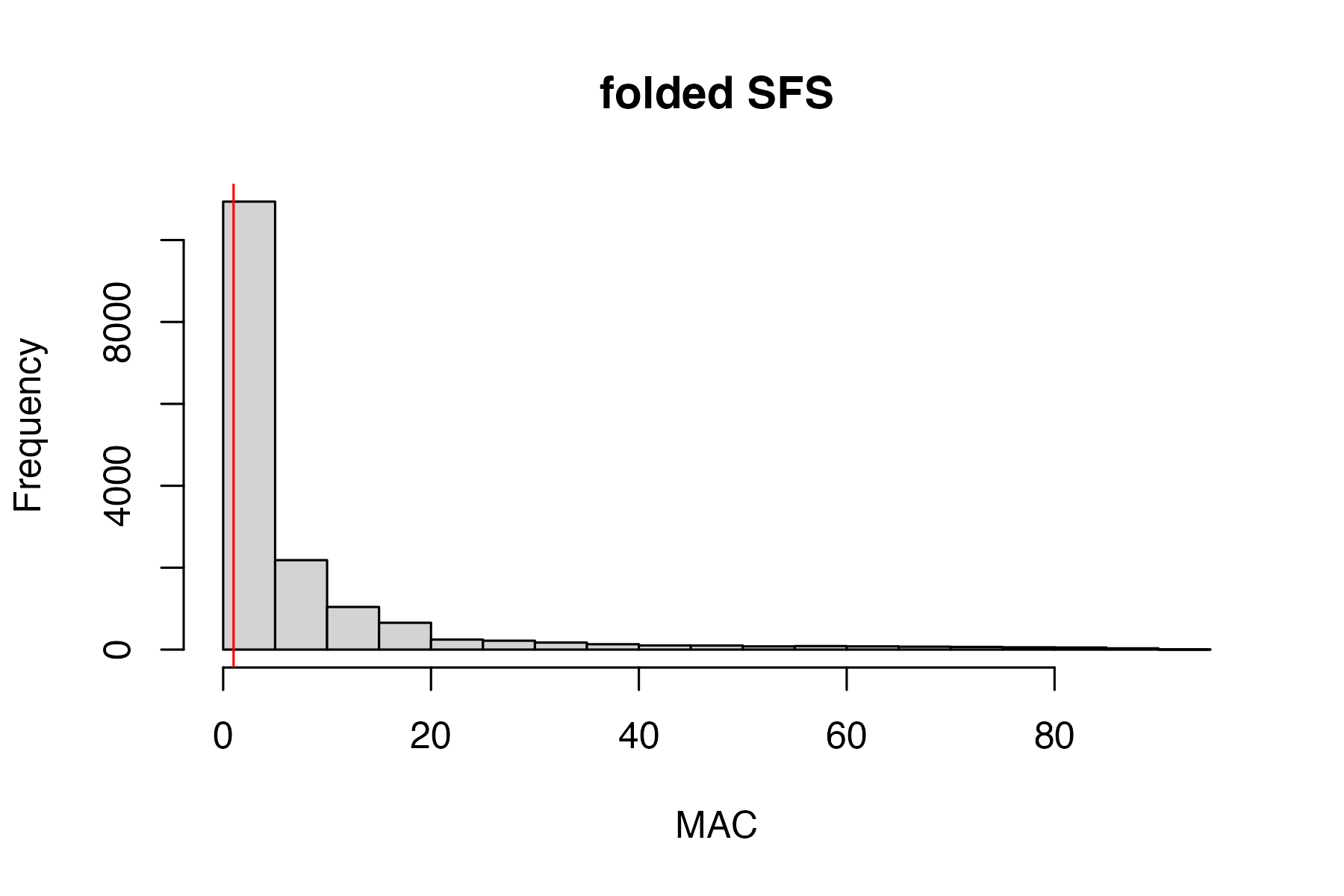
#assess clustering without MAC cutoff
miss<-assess_missing_data_tsne(vcfR, popmap, clustering = FALSE)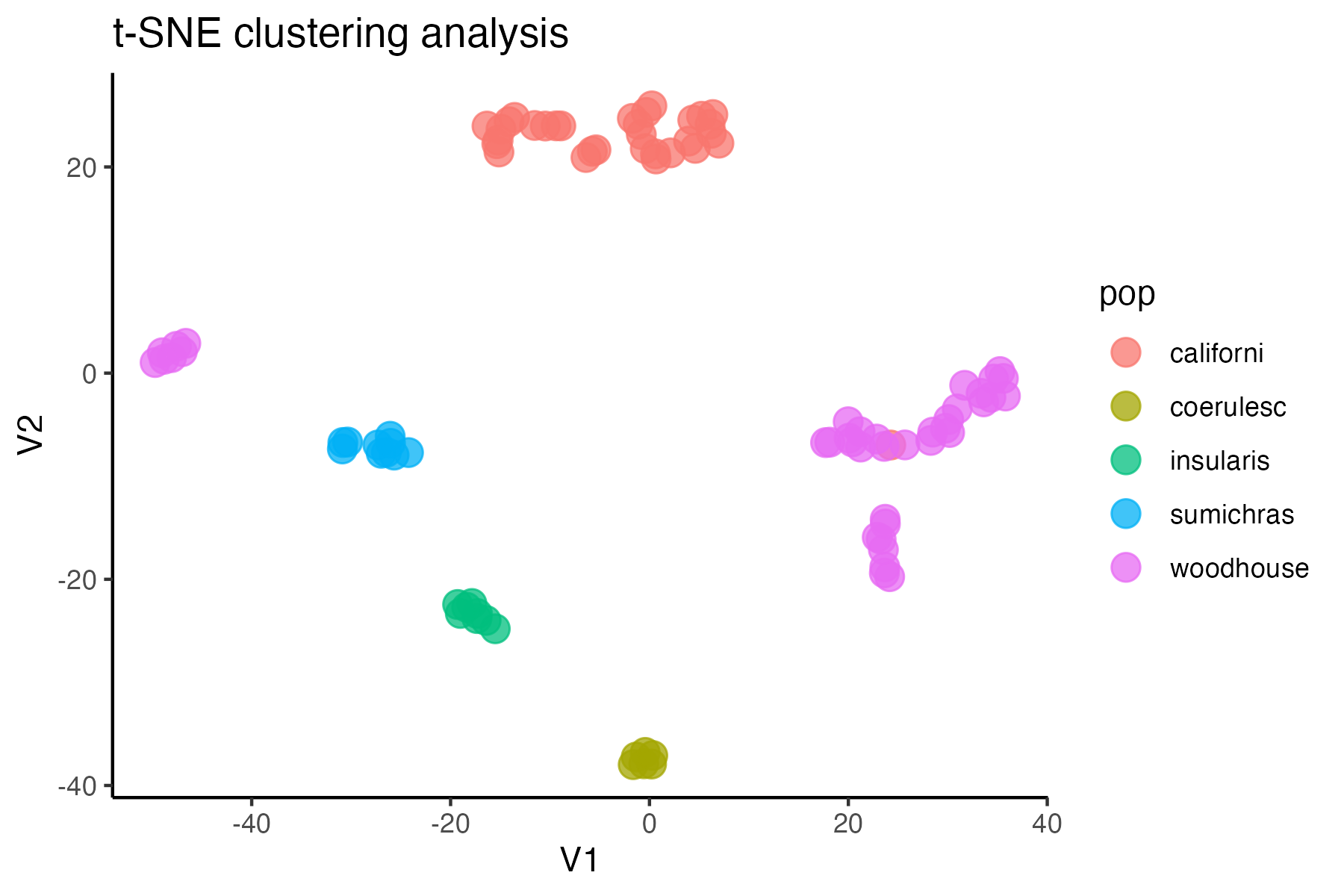
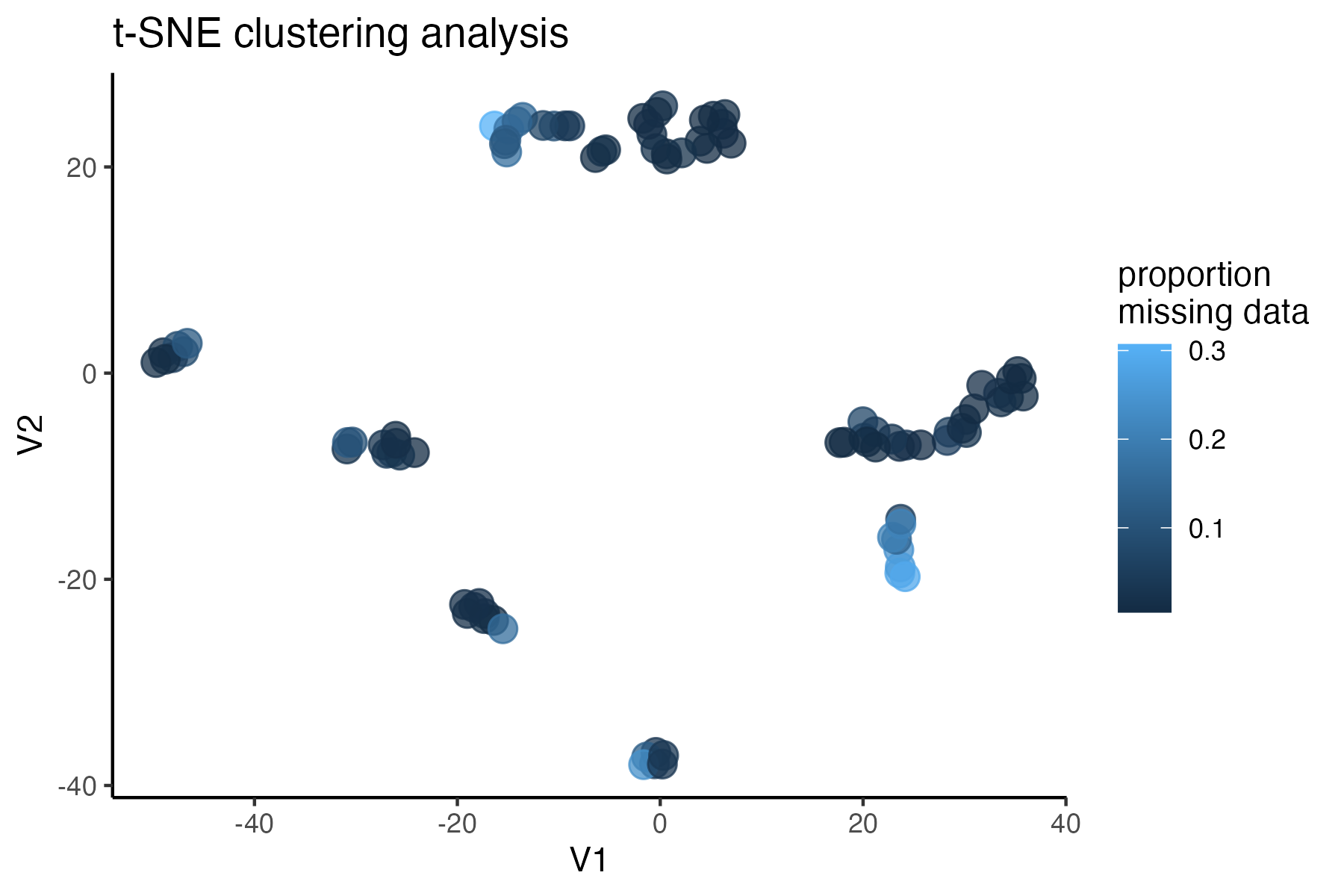
#assess clustering with MAC cutoff
miss<-assess_missing_data_tsne(vcfR.mac, popmap, clustering = FALSE)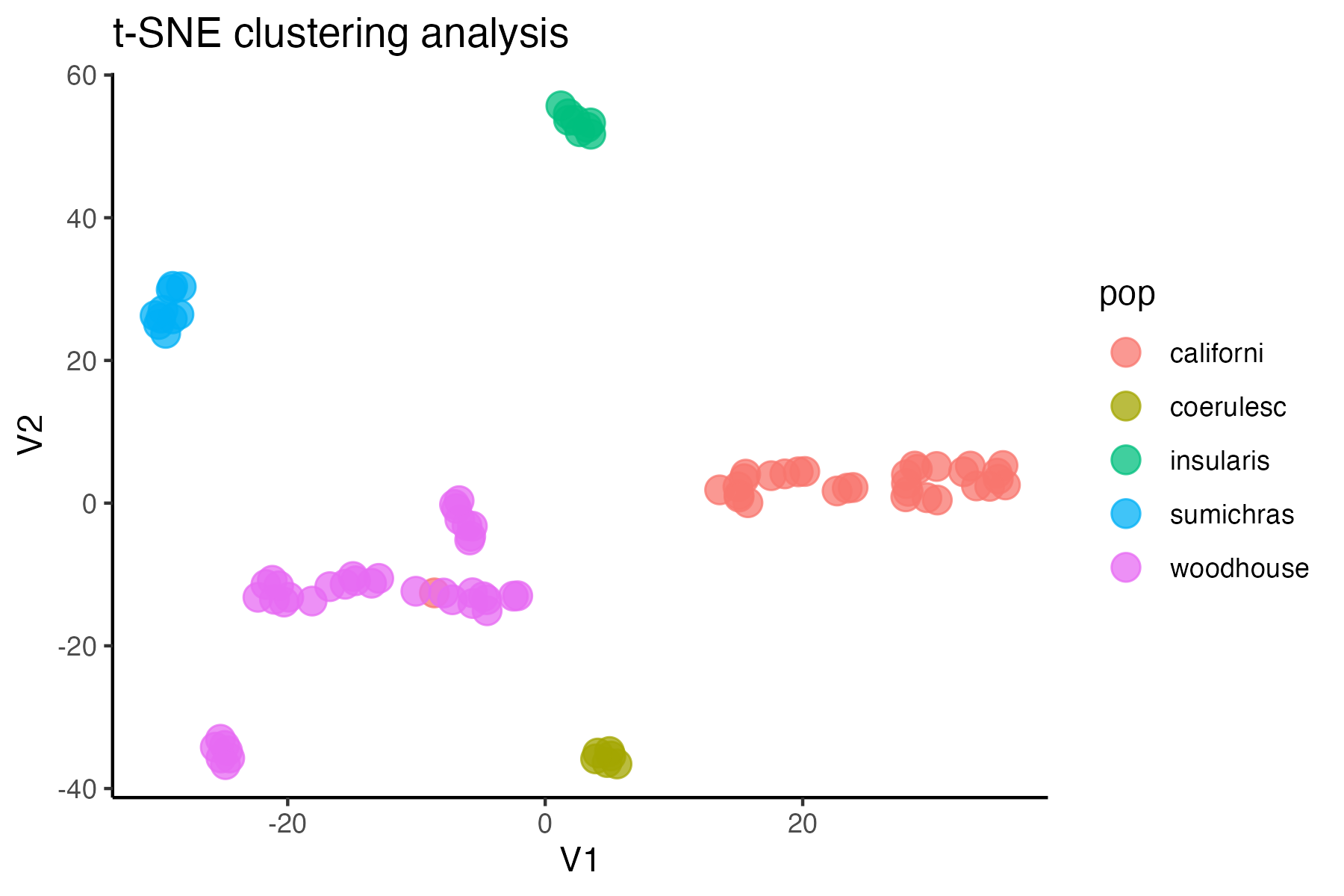
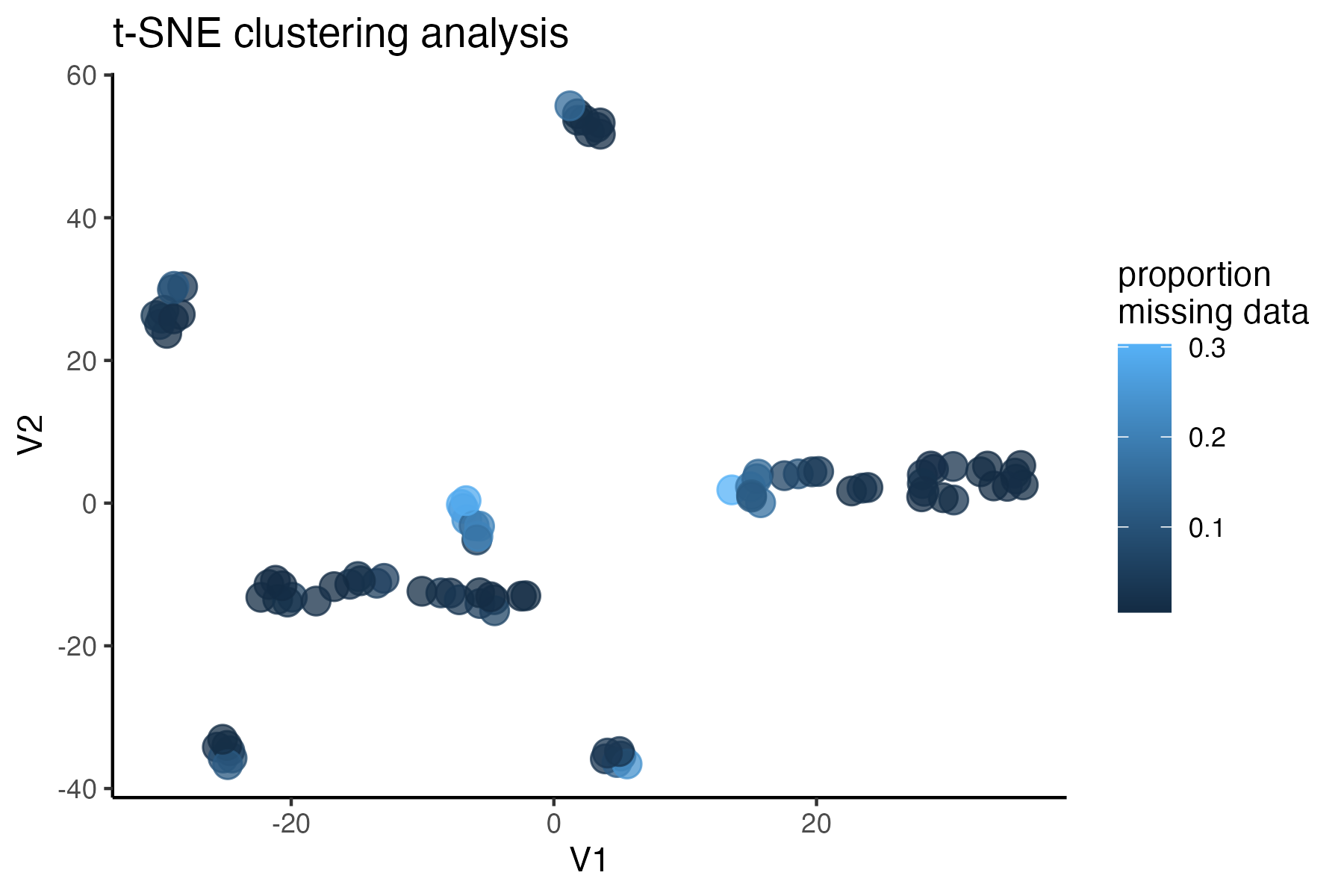
#based on these visualizations, singletons are not obviously biasing clustering patterns, so I will leave them in for now. If I want to run a program like STRUCTURE, where singletons are known to bias inference, I can write out the vcf with singletons removed as well:
#vcfR::write.vcf(vcfR.mac, file = "~/Downloads/scrub.jay.mac.vcf.gz")Finally, we will make sure that the depth and genotype quality look consistent across SNPs and samples, following our filtering pipeline.
#plot depth per snp and per sample
dp <- extract.gt(vcfR, element = "DP", as.numeric=TRUE)
heatmap.bp(dp, rlabels = FALSE)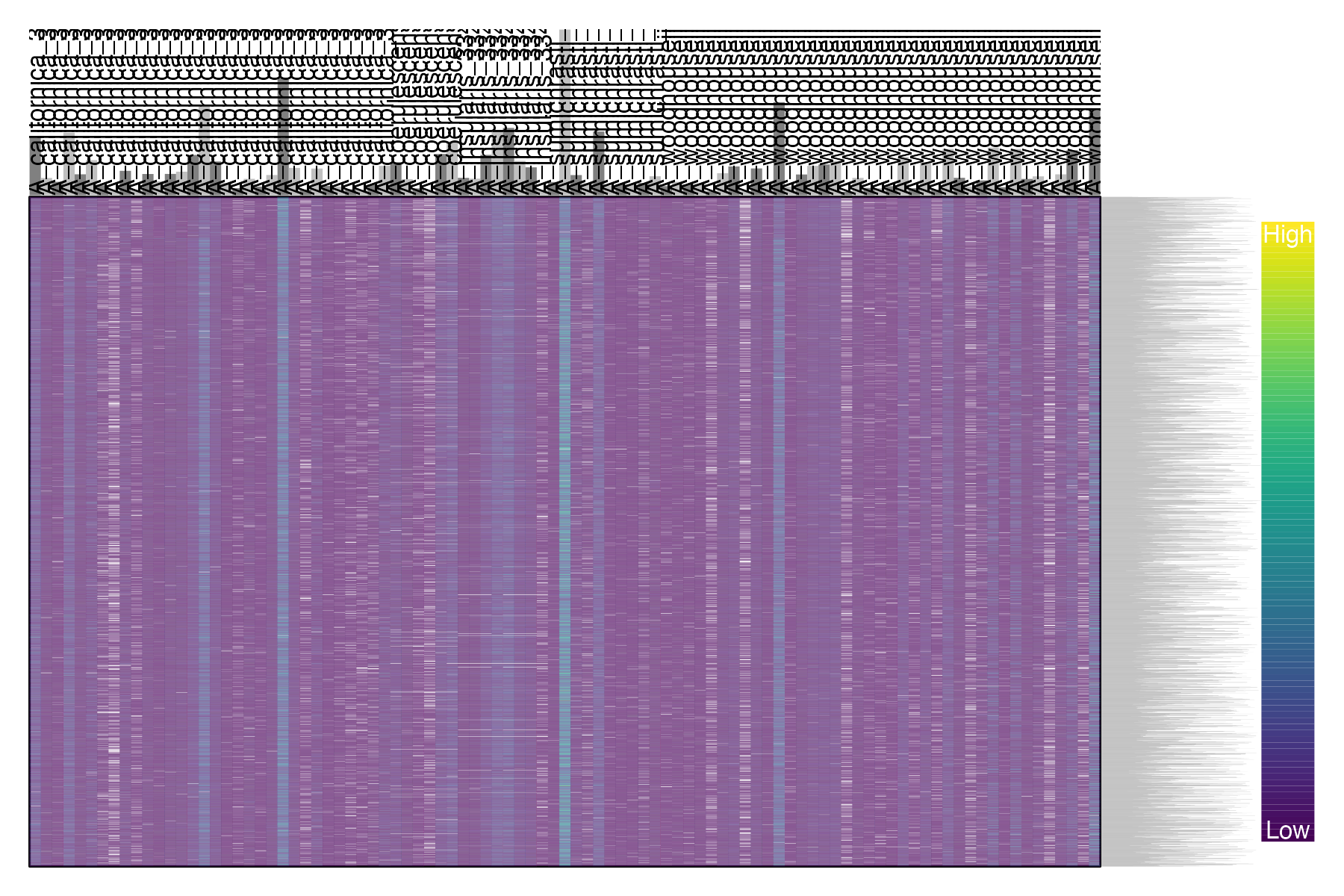
#plot genotype quality per snp and per sample
gq <- extract.gt(vcfR, element = "GQ", as.numeric=TRUE)
heatmap.bp(gq, rlabels = FALSE)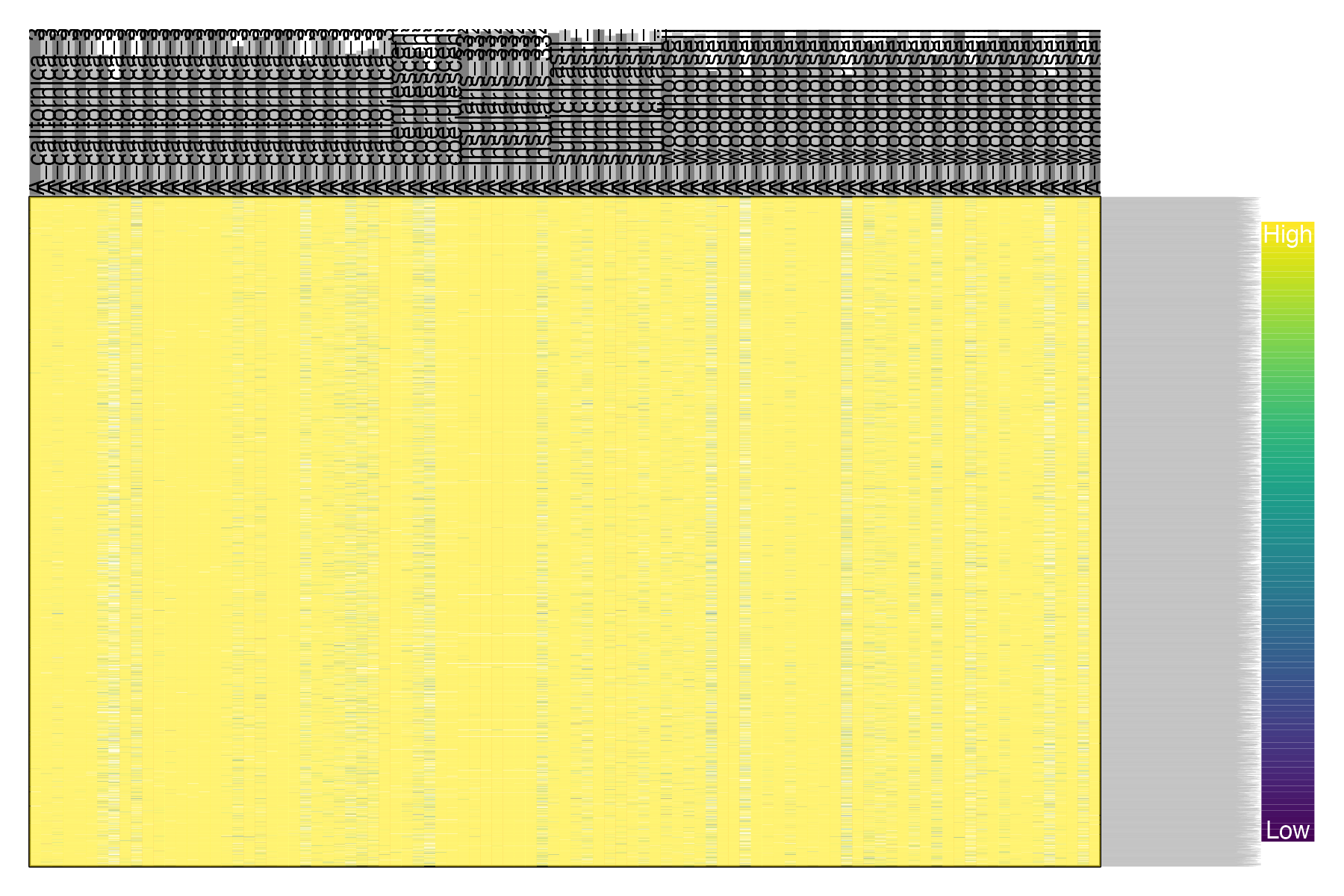
Step 6: write out vcf files for downstream analyses.
Optionally, we can use the distance_thin() function from the SNPfiltR package in order to filter our SNPs to a minimum distance between SNPs, in order to get a set of unlinked SNPs for downsteam analyses
Note:
The function vcfR::write.vcf() automatically writes a gzipped vcf file, so be sure to add the suffix .gz to the name of your output file.
Write out the filtered vcf, and a linkage filtered version, for downstream analyses
#fix mislabeled sample
colnames(vcfR@gt)[colnames(vcfR@gt) == "A_californica_334171"]<-"A_woodhouseii_334171"
#write out vcf with all SNPs
vcfR::write.vcf(vcfR, "~/Downloads/aphelocoma.filtered.vcf.gz")
#linkage filter vcf to thin SNPs to one per 500bp
vcfR.thin<-distance_thin(vcfR, min.distance = 500)
#>
|
| | 0%
|
|== | 3%
|
|==== | 6%
|
|====== | 8%
|
|======== | 11%
|
|========== | 14%
|
|============ | 17%
|
|============== | 19%
|
|================ | 22%
|
|================== | 25%
|
|=================== | 28%
|
|===================== | 31%
|
|======================= | 33%
|
|========================= | 36%
|
|=========================== | 39%
|
|============================= | 42%
|
|=============================== | 44%
|
|================================= | 47%
|
|=================================== | 50%
|
|===================================== | 53%
|
|======================================= | 56%
|
|========================================= | 58%
|
|=========================================== | 61%
|
|============================================= | 64%
|
|=============================================== | 67%
|
|================================================= | 69%
|
|=================================================== | 72%
|
|==================================================== | 75%
|
|====================================================== | 78%
|
|======================================================== | 81%
|
|========================================================== | 83%
|
|============================================================ | 86%
|
|============================================================== | 89%
|
|================================================================ | 92%
|
|================================================================== | 94%
|
|==================================================================== | 97%
|
|======================================================================| 100%
#> 2803 out of 16307 input SNPs were not located within 500 base-pairs of another SNP and were retained despite filtering
#write out thinned vcf
vcfR::write.vcf(vcfR.thin, "~/Downloads/aphelocoma.filtered.thinned.vcf.gz")